Построение нелинейной регрессионной модели в excel. Регрессия в программе Excel
Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах

3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка , выбрать точечная , а из предложенных макетов выбрать самый первый точечная с маркерами .

4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния . Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор, найти на панели макеты диаграмм и выбрать Ма кет9 , на нем ещё написано f(x)

5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции

6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет , затем сетка ). Основные изменения и настройки производятся во вкладке Макет

Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Статистическая обработка данных может также проводиться с помощью надстройки ПАКЕТ АНАЛИЗА (рис. 62).
Из предложенных пунктов выбирает пункт «РЕГРЕССИЯ » и щелкаем на нем левой кнопкой мыши. Далее нажимаем ОК.
Появится окно, показанное на рис. 63.

Инструмент анализа «РЕГРЕССИЯ » применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию ЛИНЕЙН .
Диалоговое окно «РЕГРЕССИЯ»
Метки Установите флажок, если первая строка или первый столбец входного диапазона содержит заголовки. Снимите этот флажок, если заголовки отсутствуют. В этом случае подходящие заголовки для данных выходной таблицы будут созданы автоматически.
Уровень надежности Установите флажок, чтобы включить в выходную таблицу итогов дополнительный уровень. В соответствующее поле введите уровень надежности, который следует применить, дополнительно к уровню 95%, применяемому по умолчанию.
Константа - ноль Установите флажок, чтобы линия регрессии прошла через начало координат.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите как минимум семь столбцов для выходной таблицы итогов, которая будет включать в себя: результаты дисперсионного анализа, коэффициенты, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Остатки Установите флажок для включения остатков в выходную таблицу.
Стандартизированные остатки Установите флажок для включения стандартизированных остатков в выходную таблицу.
График остатков Установите флажок для построения графика остатков для каждой независимой переменной.
График подбора Установите флажок для построения графика зависимости предсказанных значений от наблюдаемых.
График нормальной вероятности Установите флажок, для построения графика нормальной вероятности.
Функция ЛИНЕЙН
Для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем нужную функцию, например СРЗНАЧ (рис. 22).
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Можно также объединять функцию ЛИНЕЙН с другими функциями для вычисления других видов моделей, являющихся линейными в неизвестных параметрах (неизвестные параметры которых являются линейными), включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
y=m 1 x 1 +m 2 x 2 +…+b (в случае нескольких диапазонов значений x),
где зависимое значение y - функция независимого значения x, значения m - коэффициенты, соответствующие каждой независимой переменной x, а b - постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив{mn;mn-1;…;m 1 ;b}. ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
ЛИНЕЙН (известные_значения_y; известные_значения_x; конст; статистика)
Известные_значения_y - множество значений y, которые уже известны для соотношения y=mx+b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x - необязательное множество значений x, которые уже известны для соотношения y=mx+b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы_известные_значения_y и известные_значения_x могут иметь любую форму - при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив_известные_значения_x опущен, то предполагается, что этот массив {1;2;3;...} имеет такой же размер, как и массив_известные_значения_y.
Конст - логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент «конст» имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент «конст» имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y=mx.
Статистика - логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: {mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.(табл.17)
| Величина | Описание |
| se1,se2,...,sen | Стандартные значения ошибок для коэффициентов m1,m2,...,mn. |
| seb | Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент «конст» имеет значение ЛОЖЬ). |
| r2 | Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. различия между фактическим и оценочным значениями y не существует. В противоположном случае, если коэффициент детерминированности равен 0, использовать уравнение регрессии для предсказания значений y не имеет смысла. Для получения дополнительных сведений о способах вычисления r2, см. «Замечания» в конце данного раздела. |
| sey | Стандартная ошибка для оценки y. |
| F | F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
| df | Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Для получения дополнительных сведений о вычислении величины df см. «Замечания» в конце данного раздела. Далее в примере 4 показано использование величин F и df. |
| ssreg | Регрессионная сумма квадратов. |
| ssresid | Остаточная сумма квадратов. Для получения дополнительных сведений о расчете величин ssreg и ssresid см. «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика (рис. 64).

Замечания:
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m): чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять две точки прямой (x 1 ,y 1) и(x 2 ,y 2); наклон будет равен (y 2 -y 1)/(x 2 -x 1).
Y-пересечение (b): Y-пересечением прямой, обычно обозначаемым через b, является значение y для точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид y=mx+b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон: ИНДЕКС (ЛИНЕЙН(известные_значения_y; известные_значения_x); 1)
Y-пересечение: ИНДЕКС (ЛИНЕЙН (известные_значения_y; известные_значения_x); 2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель, используемая функцией ЛИНЕЙН. Функция ЛИНЕЙН использует метод наименьших квадратов для определения наилучшей аппроксимации данных. Когда имеется только одна независимая переменная x, m и b вычисляются по следующим формулам:

где x и y – выборочные средние значения, например x = СРЗНАЧ (известные_значения_x), а y = СРЗНАЧ (известные_значения_y).
Функции аппроксимации ЛИНЕЙН и ЛГРФПРИБЛ могут вычислить прямую или экспоненциальную кривую, наилучшим образом описывающую данные. Однако они не дают ответа на вопрос, какой из двух результатов больше подходит для решения поставленной задачи. Можно также вычислить функцию ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x) для прямой или функцию РОСТ(известные_значения_y; известные_значения_x) для экспоненциальной кривой. Эти функции, если не задавать аргумент новые_значения_x, возвращают массив вычисленных значений y для фактических значений x в соответствии с прямой или кривой. После этого можно сравнить вычисленные значения с фактическими значениями. Можно также построить диаграммы для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal - ssresid. Чем меньше остаточная сумма квадратов, тем больше значение коэффициента детерминированности r2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Коэффициент r2 равен ssreg/sstotal.
В некоторых случаях один или более столбцов X (пусть значения Y и X находятся в столбцах) не имеет дополнительного предикативного значения в других столбцах X. Другими словами, удаление одного или более столбцов X может привести к значениям Y, вычисленным с одинаковой точностью. В этом случае избыточные столбцы X будут исключены из модели регрессии. Этот феномен называется «коллинеарностью», поскольку избыточные столбцы X могут быть представлены в виде суммы нескольких неизбыточных столбцов. Функция ЛИНЕЙН проверяет на коллинеарность и удаляет из модели регрессии все избыточные столбцы X, если обнаруживает их. Удаленные столбцы X можно определить в выходных данных ЛИНЕЙН по коэффициенту, равному 0, и по значению se, равному 0. Удаление одного или более столбцов как избыточных изменяет величину df, поскольку она зависит от количества столбцов X, в действительности используемых для предикативных целей. Подробнее о вычислении величины df см. ниже в примере 4. При изменении df вследствие удаления избыточных столбцов значения sey и F также изменяются. Часто использовать коллинеарность не рекомендуется. Однако ее следует применять, если некоторые столбцы X содержат 0 или 1 в качестве индикатора указывающего, входит ли предмет эксперимента в отдельную группу. Если конст = ИСТИНА или значение этого аргумента не указано, функция ЛИНЕЙН вставляет дополнительный столбец X для моделирования точки пересечения. Если имеется столбец со значениями 1 для указания мужчин и 0 - для женщин, а также имеется столбец со значениями 1 для указания женщин и 0 - для мужчин, то последний столбец удаляется, поскольку его значения можно получить из столбца с «индикатором мужского пола».
Вычисление df для случаев, когда столбцы X не удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n - k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
Формулы, которые возвращают массивы, должны быть введены как формулы массива.
При вводе массива констант в качестве, например, аргумента известные_значения_x следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть различными в зависимости от параметров, заданных в окне «Язык и стандарты» на панели управления.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН , отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК . Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Функции НАКЛОН и ОТРЕЗОК возвращают ошибку #ДЕЛ/0!. Алгоритм функций НАКЛОН и ОТРЕЗОК используется для поиска только одного ответа, а в данном случае их может быть несколько.
Помимо вычисления статистики для других типов регрессии функцию ЛИНЕЙН можно использовать при вычислении диапазонов для других типов регрессии, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
На мой взгляд, как студента, эконометрика – это одна из самых прикладных наук из всех, с которыми мне удалось познакомиться в стенах своего университета. С помощью неё, действительно, можно решать задачи прикладного характера в масштабах предприятия. Насколько эффективными будут эти решения – вопрос третий. Суть в том, что большая часть знаний так и останется теорией, а вот эконометрика и регрессионный анализ всё-таки стоит изучить с особым вниманием.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;
- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».

Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.

Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.

Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.

Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.

Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.

Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»
Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.

Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением

На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:
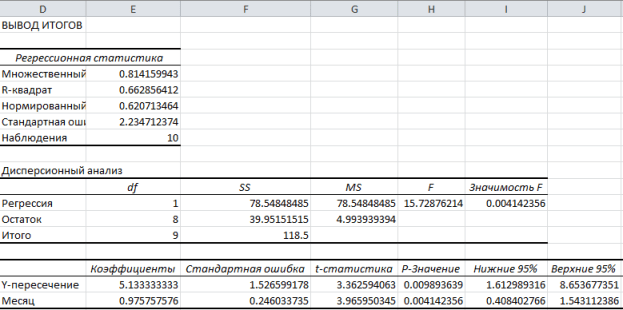
Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
Это наиболее распространенный способ показать зависимость какой-то переменной от других, например, как зависит уровень ВВП от величины иностранных инвестиций или от кредитной ставки Нацбанка или от цен на ключевые энергоресурсы .
Моделирование позволяет показать величину этой зависимости (коефициенты), благодаря которым можно делать непосредственно прогноз и осуществлять какое-то планирование, опираясь на эти прогнозы. Также, опираясь на регрессионный анализ, можно принимать управленческие решения направленные на стимулирование приоритетных причин влияющих на конечный результат, собственно модель и поможет выделить эти приоритетные факторы.
Общий вид модели линейной регрессии:
Y=a 0 +a 1 x 1 +...+a k x k
где a - параметры (коэффициенты) регрессии, x - влияющие факторы, k - количество факторов модели.
Исходные данные
Среди исходных данных нам необходим некий набор данных, который бы представлял из себя несколько последовательных или связанных между собой величин итогового параметра Y (например, ВВП) и такое же количество величин показателей, влияние которых мы изучаем (например, иностранные инвестиции).
На рисунке выше показана таблица с этими самыми исходными данными, в качестве Y выступает показатель экономически активного населения, а количество предприятий, размер инвестиций в капитал и доходов населения - это влияющие факторы, то бишь иксы.
По рисунку также можно сделать ошибочный вывод, что речь в моделировании может идти только о динамических рядах, то есть моментным рядам зафиксированных последовательно во времени, но это не так, с тем же успехом можно моделировать и в разрезе структуры, например, величины указанные в таблице могут быть разбиты не годам, а по областям.
Для построения адекватных линейных моделей желательно чтобы исходные данные не имели сильных перепадов или обвалов, в таких случаях желательно проводить сглаживание, но о сглаживании поговорим в следующий раз.
Пакет анализа
Параметры модели линейной регрессии можно рассчитать и вручную с помощью Метода наименьших квадратов (МНК), но это довольно затратно по времени. Немного быстрее это можно посчитать по этому же методу с помощью применения формул в Excel, где сами вычисления будет делать программа, но проставлять формулы все равно придется вручную.
В Excel есть надстройка Пакет анализа , который является довольно мощным инструментом в помощь аналитику. Этот инструментарий, помимо всего прочего, умеет рассчитывать параметры регрессии, по тому же МНК, всего в несколько кликов, собственно, о том как этим инструментом пользоваться дальше и пойдет речь.
Активируем Пакет анализа
По умолчанию эта надстройка отключена и в меню вкладок вы ее не найдете, поэтому пошагово рассмотрим как ее активировать.

В эксель, слева вверху, активируем вкладку Файл , в открывшемся меню ищем пункт Параметры и кликаем на него.

В открывшемся окне, слева, ищем пункт Надстройки и активируем его, в этой вкладке внизу будет выпадающий список управления, где по умолчанию будет написано Надстройки Excel , справа от выпадающего списка будет кнопка Перейти , на нее и нужно нажать.

Всплывающее окошко предложит выбрать доступные надстройки, в нем необходимо поставить галочку напротив Пакет анализа и заодно, на всякий случай, Поиск решения (тоже полезная штука), а затем подтвердить выбор кликнув по кнопочке ОК .
Инструкция по поиску параметров линейной регрессии с помощью Пакета анализа
После активации надстройки Пакета анализа она будет всегда доступна во вкладке главного меню Данные под ссылкой Анализ данных
В активном окошке инструмента Анализа данных из списка возможностей ищем и выбираем Регрессия

Далее откроется окошко для настройки и выбора исходных данных для вычисления параметров регрессионной модели. Здесь нужно указать интервалы исходных данных, а именно описываемого параметра (Y) и влияющих на него факторов (Х), как это на рисунке ниже, остальные параметры, в принципе, необязательны к настройке.

После того как выбрали исходные данные и нажали кнопочку ОК, Excel выдает расчеты на новом листе активной книги (если в настройках не было выставлено иначе), эти расчеты имеют следующий вид:

Ключевые ячейки залил желтым цветом именно на них нужно обращать внимание в первую очередь, остальные параметры значимость также немаловажны, но их детальный разбор требует пожалуй отдельного поста.
Итак, 0,865 - это R 2 - коэффициент детерминации, показывающий что на 86,5% расчетные параметры модели, то есть сама модель, объясняют зависимость и изменения изучаемого параметра - Y от исследуемых факторов - иксов . Если утрировано, то это показатель качества модели и чем он выше тем лучше. Понятное дело, что он не может быть больше 1 и считается неплохо, когда R 2 выше 0,8, а если меньше 0,5, то резонность такой модели можно смело ставить под большой вопрос.
Теперь перейдем к коэффициентам модели
:
2079,85
- это a 0
- коэффициент который показывает какой будет Y в случае, если все используемые в модели факторы будут равны 0, подразумевается что это зависимость от других неописанных в модели факторов;
-0,0056
- a 1
- коэффициент, который показывает весомость влияния фактора x 1 на Y, то есть количество предприятий в пределах данной модели влияет на показатель экономически активного населения с весом всего -0,0056 (довольно маленькая степень влияния). Знак минус показывает что это влияние отрицательно, то есть чем больше предприятий, тем меньше экономически активного населения, как бы это ни было парадоксальным по смыслу;
-0,0026
- a 2
- коэффициент влияния объема инвестиций в капитал на величину экономически активного населения, согласно модели, это влияние также отрицательно;
0,0028
- a 3
- коэффициент влияния доходов населения на величину экономически активного населения, здесь влияние позитивное, то есть согласно модели увеличение доходов будет способствовать увеличению величины экономически активного населения.
Соберем рассчитанные коэффициенты в модель:
Y = 2079,85 - 0,0056x 1 - 0,0026x 2 + 0,0028x 3
Собственно, это и есть линейная регрессионная модель, которая для исходных данных, используемых в примере, выглядит именно так.
Расчетные значения модели и прогноз
Как мы уже обсуждали выше, модель строится не только чтобы показать величину зависимостей изучаемого параметра от влияющих факторов, но и чтобы зная эти влияющие факторы можно было делать прогноз. Сделать этот прогноз довольно просто, нужно просто подставить значения влияющих факторов в место соответствующих иксов в полученное уравнение модели. На рисунке ниже эти расчеты сделаны в экселе в отдельном столбце.

Фактические значения (те что имели место в реальности) и расчетные значения по модели на этом же рисунке отображены в виде графиков, чтобы показать разность, а значит погрешность модели.
Повторюсь еще раз, для того чтобы сделать прогноз по модели нужно чтобы были известные влияющие факторы, а если речь идет о временном ряде и соответственно прогнозе на будущее, например, на следующий год или месяц, то далеко не всегда можно узнать какие будут влияющие факторы в этом самом будущем. В таких случаях, нужно еще делать прогноз и для влияющих факторов, чаще всего это делают с помощью авторегрессионной модели - модели, в которой влияющими факторами являются сам исследуемый объект и время, то есть моделируется зависимость показателя от того каким он был в прошлом.
Как строить авторегрессионную модель рассмотрим в следующей статье, а сейчас предположим, что, то какие будут величины влияющих факторов в будущем периоде (в примере 2008 год) нам известно, подставляя эти значения в расчеты мы получим наш прогноз на 2008 год.