Нейросети и примеры их использования в экономике. Нейронные сети – современный искусственный интеллект, его применение в экономике
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace . Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Что такое нейронные сети
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами - дорсальный зрительный путь и вентральный зрительный путь.Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств - это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле - это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.

Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.

Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex"a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон - это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
Компьютерное зрение
До того, как мы научились это применять к компьютерному зрению - в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга - нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.

В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей - как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х - это наше входное изображение, Y - это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.

Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.

Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Архитектура глубинной нейронной сети
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.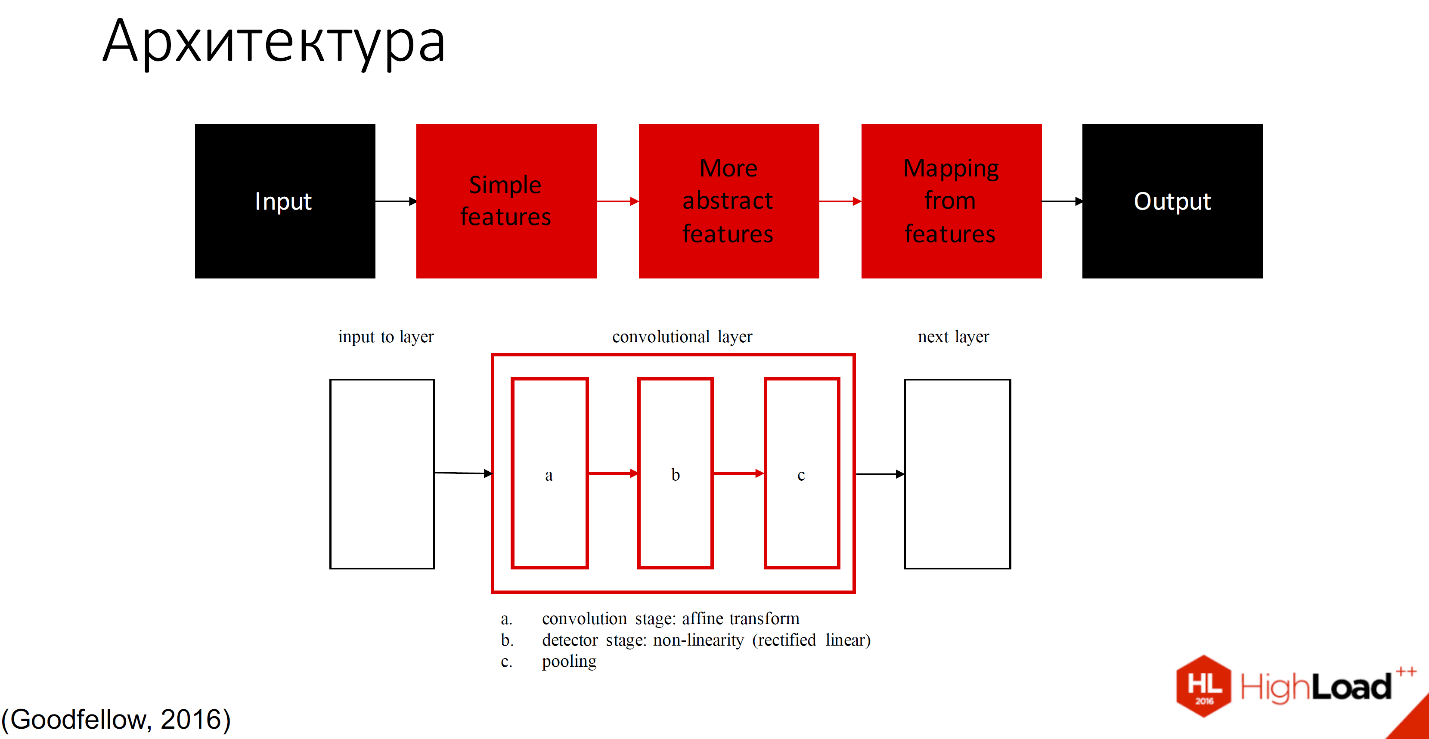
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений - один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.

Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP - многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.

Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.

С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети - это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Классические задачи сверточных нейронных сетей
Их на самом деле не так много, они относятся к трём классам. Среди них - такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ - это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания - это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ - это выделение границ, разбитых на классы.
- Выделение частей тела человека .
- И самая высокоуровневая задача - распознавание самих объектов , которое мы сейчас рассмотрим на примере распознавания лиц.
Распознавание лиц
Первое, что мы делаем - пробегаем face detector"ом по изображению для того, чтобы найти лицо. Далее мы нормализуем, центрируем лицо и запускаем его на обработку в нейронную сеть. После чего получаем набор или вектор признаков однозначно описывающий фичи этого лица.
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль - всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace - это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый - это идентификация, поиск лица по базе данных. Второе - это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection - это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям - нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition - аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Рекуррентные нейронные сети
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду - после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке - одной из самых простых эмоций - есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.

В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Обучение с подкреплением
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа - это deep reinforcement learning, обучение с подкреплением.Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически - мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение - это максимально быстрый исход игры с максимально большим счетом.
Справа вверху - последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым - нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память - то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.

Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных - это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Нестандартные применения нейронных сетей
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet"е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите - самый последний кадр - реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги - все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить - семантическая сегментация 3D изображений в медицине. Вообще medical imaging - это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали - ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах - вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.

Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
- Введение
- Заключение
- Введение
- Благотворное влияние на развитие нейросетевых технологий оказало создание методов параллельной обработки информации.
- Необходимо выразить признательность замечательному хирургу, философу и кибернетику Н.М. Амосову, вместе с учениками систематизировавшему подход к созданию средств искусственного интеллекта (ИИ). Этот подход заключается в следующем.
- В основе стратегий ИИ лежит понятие парадигмы -- взгляда (концептуального представления) на суть проблемы или задачи и принцип ее решения. Рассматривают две парадигмы искусственного интеллекта.
- 1. Парадигма эксперта предполагает следующие объекты, а также этапы разработки и функционирования системы ИИ:
- * форматизация знаний -- преобразование экспертом проблемного знания в форму, предписанную выбранной моделью представления знаний;
- * формирование базы знаний <БЗ) - вложение формализованных знаний в программную систему;
- * дедукция -- решение задачи логического вывода на основе БЗ.
- Эта парадигма лежит в основе применения экспертных систем, систем логического вывода, в том числе на языке логического программирования ПРОЛОГ. Считается, что системы на основе этой парадигмы более изучены.
- 2. Парадигма ученика, включающая следующие положения и последовательность действий:
- * обработка наблюдений, изучение опыта частных примеров -- формирование базы данных <БД> системы ИИ;
- * индуктивное обучение -- превращение БД в БЗ на основе обобщения знаний, накопленных в БД. и обоснование процедуры извлечения знаний из БЗ. Это означает, что на основе данных делается вывод об общности той зависимости между объектами, которую мы наблюдаем. Основное внимание здесь уделяется изучению аппроксимирующих, вероятностных и логических механизмов получения общих выводов из частных утверждений. Затем мы можем обосновать, например, достаточность процедуры обобщенной интерполяции (экстраполяции), или процедуры ассоциативного поиска, с помощью которой будем удовлетворять запросы к БЗ;
- * дедукция -- по обоснованной или предполагаемой процедуре мы выбираем информацию из БЗ по запросу (например, оптимальную стратегию управления по вектору, характеризующему сложившуюся ситуацию).
- Исследования в рамках этой парадигмы и ее разработка проведены пока слабо, хотя они лежат в основе построения самообучающихся систем управления (ниже будет приведен замечательный пример самообучающейся системы управления -- правила стрельбы в артиллерии).
- Чем база знаний, общий и обязательный элемент системы ИИ, отличается от базы данных? Возможностью логического вывода!
- Теперь обратимся к «естественному» интеллекту. Природа не создала ничего лучшего, чем человеческий мозг. Значит, мозг является и носителем базы знаний, и средством логического вывода на ее основе независимо оттого, по какой парадигме мы организовали свое мышление, т. е. каким способом заполняем базу знаний. -- учимся!
- Д.А. Поспелов в замечательной, единственной в своем роде, работе освещает высшие сферы искусственного интеллекта -- логику мышления. Цель данной книги -- хотя бы частично препарировать нейросеть как средство мышления, тем самым привлекая внимание к низшему, начальному звену всей цепи методов искусственного интеллекта.
- Отбросив мистику, мы признаем, что мозг представляет собой нейронную сеть, нейросеть, - нейроны, соединенные между собой, со многими входами и единственным выходом каждый. Нейрон реализует достаточно простую передаточную функцию, позволяющую преобразовать возбуждения на входах, с учетом весов входов, в значение возбуждения на выходе нейрона. Функционально законченный фрагмент мозга имеет входной слой нейронов -- рецепторов, возбуждаемых извне, и выходной слой, нейроны которого возбуждаются в зависимости от конфигурации и величины возбуждения нейронов входного слоя. Предполагается, что нейросеть. имитирующая работу мозга, обрабатывает не сами данные, а их достоверность, или, в общепринятом смысле, вес, оценку этих данных. Для большинства непрерывных или дискретных данных их задание сводится к указанию вероятности диапазонов, которым принадлежат их значения. Для большого класса дискретных данных -- элементов множеств -- целесообразно жесткое закрепление нейронов входного слоя.
1. Опыт применения нейронных сетей в экономических задачах
С помощью нейронных сетей нами решается задача разработки алгоритмов нахождения аналитического описания закономерностей функционирования экономических объектов (предприятие, отрасль, регион). Эти алгоритмы применяются к прогнозированию некоторых «выходных» показателей объектов. Решается задача нейросетевой реализации алгоритмов. Применение методов распознавания образов или соответствующих нейросетевых методов позволяет решить некоторые назревшие проблемы экономико-статистического моделирования, повысить адекватность математических моделей, приблизить их к экономической реальности. Использование распознавания образов в комбинации с регрессионным анализом привело к новым типам моделей - классификационным и кусочно-линейным. Нахождение скрытых зависимостей в базах данных - это основа задач моделирования и обработки знаний, в том числе для объекта с трудно формализуемыми закономерностями.
Выбор наиболее предпочтительной модели из некоторого их множества можно понимать либо как задачу ранжирования, либо как задачу выбора на основе набора правил.. Практика показала, что методы, основанные на использовании априорных весов факторов и поиске модели, отвечающего максимальной взвешенной сумме факторов, приводит к необъективным результатам. Веса - это то, что надо определить, в этом и состоит задача. Причем наборы весов локальны - каждый из них годится только для данной конкретной задачи и данного объекта (группы объектов).
Рассмотрим задачу выбора искомой модели подробнее. Предположим, что имеется некоторое множество объектов М, деятельность которых направлена на достижение некоторой цели. Функционирование каждого объекта характеризуется значениями n признаков, то есть существует отображение ф: М -> Rn. Следовательно, наш исходный пункт - вектор состояния экономического объекта: x = . Показатели качества функционирования экономического объекта: f0(x), f1(x),…,fm(x). Эти показатели должны находиться в определенных пределах, а некоторые из них мы стремимся сделать либо минимальными, либо максимальными.
Такая общая постановка может быть противоречивой, и необходимо применять аппарат развязки противоречий и приведения постановки задачи к корректной форме, согласованной с экономическим смыслом.
Мы упорядочиваем объекты с точки зрения некоторой критериальной функции, но критерий, как правило, плохо определен, размыт и возможно противоречив.
Рассмотрим задачу моделирования эмпирических закономерностей по ограниченному числу экспериментальных и наблюдаемых данных. Математическая модель может быть уравнением регрессии или диагностическим правилом, или правилом прогнозирования. При малой выборке эффективнее метолы распознавания. При этом влияние управления факторами учитывается с помощью вариации значений факторов при их подстановке в уравнение закономерности или в решающее правило диагностики и прогнозирования. Кроме того, мы применяем отбор существенных признаков и генерирование полезных признаков (вторичных параметров). Этот математический аппарат нужен для прогнозирования и диагностики состояний экономических объектов.
Рассмотрим нейронную сеть с точки зрения теории комитетных конструкций, как на коллектив нейронов (индивидуумов. Нейронная сеть как механизм оптимизации работы нейронов при коллективных решениях это способ согласования индивидуальных мнений, при котором коллективное мнение является правильной реакцией на вход, то есть нужной эмпирической зависимостью.
Отсюда следует оправданность применения комитетных конструкций в задачах выбора и диагностики. Идея состоит в том, чтобы вместо одного решающего правила искать коллектив решающих правил, этот коллектив вырабатывает коллективное решение в силу процедуры, обрабатывающей индивидуальные решения членов коллектива. Модели выбора и диагностики как правило приводят к несовместным системам неравенств, для которых вместо решений надо искать обобщения понятия решения. Таким обобщением является коллективное решение.
Так, например, комитет системы неравенств - это такой набор элементов, что каждому неравенству удовлетворяет большинство злементов этого набора. Комитетные конструкции - некоторый класс обобщений понятия решения для задач, которые могут быть как совместными, так и несовместными. Это класс дискретных аппроксимаций для противоречивых задач, их можно также соотнести с размытыми решениями. Метод комитетов в настоящее время определяет одно из направлений анализа и решения задач эффективного выбора вариантов, оптимизации, диагностики и классификации. Приведём для примера определение одной из основных комитетных конструкций, а именно: для 0 < p < 1: p - комитетом системы включений называется такой набор элементов, что каждому включению удовлетворяет более чем р - я часть этого набора.
Комитетные конструкции можно рассматривать и как некоторый класс обобщений понятия решения на случай несовместных систем уравнений, неравенств и включений, и как средство распараллеливания в решении задач выбора, диагностики и прогнозирования. Как обобщение понятия решения задачи комитетные конструкции представляют собой наборы элементов, обладающие некоторыми (но, как правило, не всеми) свойствами решения, это вид размытых решений.
Как средство распараллеливания комитетные конструкции непосредственно выступают в многослойных нейронных сетях. Нами показано, что для обучения нейронной сети точному решению задачи классификации можно применить метод построения комитета некоторой системы аффинных неравенств.
Исходя из сказанного, можно заключить, что метод комитетов связан с одним из важных направлений исследования и численного решения как задач диагностики и выбора вариантов, так и задач настройки нейронных сетей с целью получения требуемого их реагирования на входную информацию по той или иной проблеме лица, принимающего решения.
В процессе эксплуатации метода комитетов выявились такие его важные для прикладных задач свойства как эвристичность, интерпретируемость, гибкость - возможность дообучения и перенастройки, возможность использования наиболее естественного класса функций - кусочно-аффинных, причем для постановки задачи классификации, диагностики и прогнозирования требуется лишь корректность, то есть, чтобы один и тот же объект не был отнесен к разным классам.
Другая сторона вопроса о комитетных конструкциях связана с понятием коалиций при выработке коллективных решений, при этом ситуации резко различаются в случае коллективных предпочтений (здесь много подводных камней) и в случае правил коллективной классификации, в этом случае процедуры можно строго обосновать и они имеют более широкие возможности. Поэтому важно уметь сводить задачи принятия решений и задачи прогнозирования к классификационным задачам.
2. Табличный метод - основа искусственного интеллекта
В общем-то, принципы мозговой деятельности известны и активно используются. Мы применяем незримые таблицы в нашей памяти, принудительно и вольно заполняемые за партой, за рулем, с министерским портфелем и без него, крутя головой на шумной улице, за книгой, у станка и у мольберта. Мы учимся, учимся всю жизнь: и школьник, проводящий бессонные ночи за букварем, и умудренный опытом профессор. Ибо с теми же таблицами мы связываем не только принятие решений, но и двигаемся, ходим, играем в мяч.
Если противопоставить ассоциативному мышлению математические вычисления, то каков же их вес в жизни человека? Как шло развитие человека, когда он вообще, не умел считать? Пользуясь ассоциативным мышлением, умея интерполировать и экстраполировать, человек накапливал опыт. (Кстати, вспомним тезис Д. Менделеева: Наука начинается тогда, когда начинают считать.) Можно спросить читателя: Сколько раз сегодня Вы считали? Вы водили автомобиль, играли в теннис, торопились на автобус, планируя свои действия. Представляете, сколько бы Вам пришлось высчитывать (да еще где взять алгоритм?), для того чтобы поднять ногу на тротуар, минуя бордюр? Нет, мы ничего не вычисляем ежеминутно, и это, пожалуй, основное в нашей интеллектуальной жизни, даже в науке и бизнесе. Механизмы ощущений, интуиции, автоматизма, которые мы, не в силах объяснить, адресуем подкорковому мышлению, на деле являются нормальными механизмами ассоциативного мышления с помощью таблиц базы знаний.
И главное, мы делаем это быстро! Как же нам не задуматься, пытаясь постичь и воспроизвести развитию образной памяти, продукт роста в процессе Развития. Мы полагаем это вполне материально воплощенным и потому реализуемым искусственно, подвластным моделированию и воспроизведению.
Сформулируем теперь достаточный, сегодняшний принцип построения нейросети, как элемента ИИ:
1. Следует признать, что основа имитации нейро-структуры мозга -- это метод табличной интерполяции.
2. Таблицы заполняются или по известным алгоритмам вычислений, или экспериментально, или экспертами.
3. Нейросеть обеспечивает высокую скорость обработки таблиц за счет возможности лавинообразного распараллеливания.
4. Кроме того, нейросеть допускает вход в таблицу с неточны- ми и неполными данными, обеспечивая приблизительный ответ по принципу максимальной или средней похожести.
5. Задача нейросетевой имитации мозга заключается в преобразовании не самой исходной информации, а оценок этой информации, в подмене информации величинами возбуждения рецепторов, искусно распределенных между видами, типами, параметрами, диапазонами их изменения или отдельными значениями.
6. Нейроны выходного слоя каждой подструктуры своим возбуждением указывают на соответствующие решения. В то же время эти сигналы возбуждения на правах исходной опосредованной информации могут использоваться в следующем звене логической цепочки без внешнего вмешательства в рабочем режиме.
3. Мониторинг банковской системы
В приводится пример блистательного применения самоорганизующихся карт Кохонена (SOM -- Self-Organizing Map) для исследования банковской системы России в 1999 -- 2000 гг.
В основе мониторинга лежит рейтинговая оценка на основе автоматического выполнения одной процедуры: по многомерному вектору параметров банков на экране компьютера высвечивает. Обращается внимание на то, что нейросетевые технологии позволяют строить наглядные функции многих переменных, как бы преобразуя много- мерное пространство в одно-, двух- или трехмерное. Для каждого отдельно взятого исследования различных факторов необходимо строить свои SOM. Прогноз возможен лишь на основе анализа временного ряда оценок SOM. Новые SOM необходимы и для продления цепочки выводов, с подключением данных извне, например политического характера.
Такой подход, несомненно, эффективен и результативен. Но представляется, что по сравнению с потенциалом мозговых нейроструктур он сдерживает размах и смелость мысли, не позволяет тянуть длинные цепочки посылка-следствие, совмещать анализ с прогнозом, оперативно учитывать складывающуюся ситуацию и вводить в рассмотрение новые факторы и опыт экспертов. Следует согласиться с тем, что мозгу все это подвластно, и мы вновь обращаемся к его структурам, предлагая проект программных средств системы мониторинга.
Структура нейросети и способы обучения. Логические функции, лежащие в основе мониторинга, преимущественно основаны на конъюнкции логических значений переменных, отображающих диапазоны изменения параметров или показателей банков.
В представлены следующие показатели:
* собственный капитал;
* сальдированные активы;
* ликвидные активы;
* обязательства до востребования;
* вклады населения;
* коэффициент ликвидности;
* бюджетные средства.
Можно расширить систему показателей:
* объем инвестиций в эпоху бурно развивающейся экономики;
* объем прибыли;
* прошлый рейтинг и значение миграции;
* отчисления в фонд поддержки науки и образования;
* налоговые отчисления;
* отчисления в пенсионный фонд;
* отчисления в благотворительный и культурный фонд;
* участие в программах ЮНЕСКО и т.д.
Такой простой вид логической функции при переходе в область действительных переменных говорит о достаточности однослойной нейросети, содержащей входной слой рецепторов и выходной слой, на котором формируются результаты мониторинга.
При построении входного слоя необходимо учитывать не только текущие показатели, но и динамику изменения рейтинга за прошлые периоды времени. Выходной слой должен отражать не только рейтинг, но и экспертные рекомендации, а также другие решения и выводы.
Целесообразен простейший вид обучения -- построение базы знаний, который соответствует концепции создания нейросети под задачу: непосредственное введение связей оператором-исследователем вручную -- от рецепторов к нейронам выходного слоя в соответствии с причинно-следственными связями. Тем самым сеть создается уже обученной.
Тогда передаточная функция тоже будет простейшей и основанной на суммировании величин возбуждения на входе нейрона, умноженных на вес связи:
Задание веса связей га по сравнению с грубым заданием всех весов, равных единице, целесообразнее в связи с возможным желанием оператора или эксперта в разной степени учитывать влияние различных показателей.
Порог h отсекает заведомо неприемлемые выводы, упрощая дальнейшую обработку (например, нахождение среднего). Коэффициент приведения к обусловлен следующими соображениями.
Максимальное значение V может достигать п. Для того чтобы значение рейтинга находилось в некотором приемлемом диапазоне, например в , значения возбуждения надо преобразовать, положив к = Уп.
Принятые выше допущения позволяют оперативно вводить изменения и уточнения оператором -- экспертом -- пользователем, развивать сеть, вводя новые факторы и учитывая опыт. Для этого оператору достаточно, щелкнув мышью, выделить рецептор, а затем нейрон выходного слоя и связь установлена! Осталось только приблизительно назначить вес введенной связи из диапазона .
Здесь следует сделать очень Важное Замечание (ОВЗ), касательно всего материала книги и предназначенное очень внимательному читателю.
Ранее, рассматривая обучение, мы четко классифицировали исходные эталонные ситуации, принимая достоверность каждого компонента, равной единице. Проводя затем трассировку и прокладывая динамические пути возбуждения, мы также полагали веса связей, равными единице (или некоторому максимальному постоянному значению). Но ведь учитель сразу может получить дополнительную степень свободы, принимая во внимание факторы в той степени и с теми весами, которые он задаст! Сделаем допущение, что разные факторы в разной степени влияют на результат, и такое влияние заложим на этапе обучения принудительно.
Например, известно, что накануне войны население в огромном количестве закупает мыло, спички и соль. Значит, наблюдая за этим фактором, можно прогнозировать скорое начало войны.
Создавая нейросеть для анализа исторических или социальных событий, следует выделить один или несколько рецепторов, возбуждение которых соответствует разному уровню закупок мыла, соли и спичек одновременно. Возбуждение этих рецепторов должно передаваться, влиять (наряду с другими факторами) на степень возбуждения нейрона выходного слоя, соответствующего заявлению Скоро война!
Тем не менее, интенсивная закупка мыла, спичек и соли необходимое, но не такое уж достаточное условие наступления войны. Оно может свидетельствовать, например, о бурном возрождении туризма в район Главного хребта Кавказа. В словах не такое уж заключается смысл нечеткой логики , позволяющей учитывать не непреложность события, не булеву переменную да -- нет, а некоторое промежуточное, неопределенное, взвешенное состояние типа "влияет, но не так уж, прямо, что обязательно...". Поэтому связи (все или некоторые), исходящие из данного (данных) рецептора, положим равными некоторой предполагаемой величине, меньшей единицы и корректируемой впоследствии, которая отражает влияние возбуждения рецептора на вывод.
Таким образом, одновременная закупка мыла, соли и спичек учитывается дважды: уровень закупки будет отображен в степени возбуждения соответствующих рецепторов, а характер влияния закупки на вывод Скоро война! - с помощью весов синапсических связей.
Согласитесь, что при построении одноуровневых сетей такой подход напрашивается сам собой и реализуется предельно просто.
Структура экрана рецепторов. Основную часть его составляет окно прокрутки, в котором можно просматривать и задавать состояние рецепторного слоя, несомненно, не способного поместиться на статическом экране.
В окне прокрутки указаны показатели и их оценочные значения в диапазоне для соответствующих рецепторов. Это вероятностные значения, основанные на достоверности, интуиции, экспертных оценках. Оценки предполагают охват нескольких рецепторов. Например, оценка того, что собственный капитал составляет не то 24, не то 34, не то 42 тыс. у. е., но скорее всетаки 24, может привести к приблизительной оценке задаваемых величин возбуждения 0.6,0.2 и 0.2 рецепторов, соответствующих диапазонам (20 - 25], (30 - 35], (40 - 45]. На экране отображены статически задаваемые показатели, такие, как рейтинг в результате прошлых измерений, выборочные ранее найденные показатели, а также показатели политической, социальной и экономической конъюнктуры. (Их обилие и развитие могут все-таки потребовать прокрутки.)
Следует также отобразить управление прокруткой и меню основных действий:
* переход на экран выходного слоя;
* статистическая обработка результатов (предполагает переход к выходному экрану);
* введение новой связи;
* введение нового рецептора;
* введение нового нейрона выходного слоя (предполагает переключение экранов);
* введение нового показателя и т.д.
Структура экрана выходного слоя. Экран выходного слоя (рис.8.3) отображает систему концентрических (вложенных) прямоугольников или других плоских фигур, отражающих распространение рейтинга по убыванию. В центре экрана яркими точками отмечены самые преуспевающие банки или предполагаемые идеальные образы. Каждому элементу экрана жестко соответствует нейрон выходного слоя. В результате мониторинга может максимально возбудиться нейрон, соответствующий эталону, однако, скорее всего, высветится точка экрана, не совпадающая ни с каким эталоном, являющаяся промежуточной или усредненной.
Рис. - 8.3. Экран выходного слоя
Несомненно, следует предусмотреть меню для операции усредненной оценки рейтинга, демонстрации категории преуспевания, выдачи сигналов предупреждения, текстов заключений, рекомендуемых стратегий развития, сохранения данных для дальнейшего развития и т.д.
Обучение нейросети. Для обучения нейросети на основе экспертных оценок следует задать диапазоны допустимых параметров, позволяющие считать банк идеально преуспевающим, имеющим максимальный рейтинг. Фиксируя несколько точек, координаты которых (множества значений параметров) удовлетворяют допустимым значениям рейтинга для известных или предполагаемых (с учетом возможных вариантов) банков, можно получить несколько идеальных представителей. Соответствующие им нейроны, т.е. элементы экрана выходного слоя, выделяют произвольно, рассредоточивая по области экрана. Желательно, чтобы эталоны с большим рейтингом располагались ближе к центру.
Далее переходят к подобному же заполнению охватывающего прямоугольника, на основе следующей рейтинговой категории и т.д. до банков-аутсайдеров.
Для проведения подобной работы экспертами предварительно формируется таблица (табл. 1).
Нейронам, отображающим банки, на экране соответствуют величины их возбуждения -- рейтинги.
Методика мониторинга. Обученная система, которая поступает в распоряжение пользователя после высококвалифицированной экспертизы экономистов и политиков, готова к использованию в рамках CASE-технологии CASE -- Computer Aided Software Engineering .
Таблица 1 - Экспертные оценки для обучения нейросети
При этом пользователь реализует свое право на дополнительное обучение, уточнение (например, весов связей, для усиления или ослабления влияния некоторых показателей на основе собственного опыта), введение дополнительных показателей для эксперимента на свой риск и т.д.
Предположим, пользователь исследует ситуацию, сложившуюся вокруг банка "Инвест-Туда-и-Обратно". Естественно, он не располагает сколько-нибудь удовлетворительной информацией о целесообразности собственных вложений и поэтому приступает к скрупулезному сбору данных, в результате чего получает приблизительные, вероятные, разноречивые характеристики для моделирования.
С помощью экрана рецепторов пользователь задает значения их возбуждения исходя из вполне достоверных данных, но иногда учитывая варианты или -- или (частично возбуждая разные рецепторы), иногда по наитию, иногда просто пропуская показатели. Такие показатели, как рейтинг в прошлом и миграция, пока неизвестны, но полученный результат предполагается использовать в дальнейшем.
После ввода данных на экране выходного слоя яркая точка вблизи области аутсайдеров красноречиво свидетельствует о защите гражданского права ненасильственного выбора решения о целесообразности вложения праведно накопленного капитала.
Координаты этой точки на экране определяются по известной формуле нахождения среднего по координатам высветившихся нейронов тех банков, которым близок контролируемый банк, и по величинам их возбуждения. Но по этим же формулам на основе рейтингов высветившихся банков находится рейтинг исследуемого банка!
Пользователь может принять решение о дополнении базы знаний и, следовательно, нейросети информацией о новом банке, что целесообразно, если совет экспертов подверг существенной критике получившийся результат и указывает тем самым на ошибку нейросети. Достаточно только воспользоваться опцией. Дополнить, в результате выполнения которой инициируется диалог компьютера с пользователем:
- Вы хотите изменить рейтинг -- Да.
- Новое значение рейтинга --...
- Сохранить!
Тогда нейрон выходного слоя с найденными координатами ставится в соответствие новому банку. Формируются его связи с теми рецепторами, которым было сообщено возбуждение при вводе информации о банке. Вес каждой связи полагается равным введенной пользователем величине возбуждения соответствующего нейрона-рецептора. Теперь база знаний дополнена таким же образом, как список пристрелянных установок артиллерийской батареи после поражения очередной цели.
Однако значительное принудительное изменение рейтинга может потребовать перемещения высветившейся точки в область банков с соответствующим уровнем рейтинга, т.е. необходимо за данным банком закрепить другой нейрон выходного слоя, в другой области экрана. Это также устанавливается в результате диалога компьютера с пользователем.
Корректировка и развитие. Выше мы уже упоминали о необходимости и возможности постоянного уточнения и развития нейросети. Можно изменять представление о продвинутости банка-эталона (реального или идеального) и дополнять базу знаний, т.е. данную нейросеть. Можно корректировать веса связей как меры влияния отдельных показателей на выходной результат.
Можно вводить новые показатели с их весами, рассматривать новые решения и устанавливать степень влияния на них тех же или новых показателей. Можно приспособить нейросеть для решения смежных задач с учетом влияния отдельных показателей на миграцию банков (переход с одного рейтингового уровня на другой) и т.д.
Наконец, можно, приобретя данный программный продукт с дружественным интерфейсом и прекрасным сервисом, с развитым набором функций преобразования нейросети, переделать ее для совершенно другой задачи, например для увлекательной игры в железнодорожную рулетку, на которой мы намерены остановиться ниже.
В заключение отметим, что в экономике и бизнесе, а также в управлении сложными объектами преобладают системы принятия решений, где каждая ситуация образуется на основе неизменного числа факторов. Каждый фактор представлен вариантом или значением из исчерпывающего множества, т.е. каждая ситуация представляется конъюнкцией, в которой обязательно участвуют высказывания относительно всех факторов, по которым формируется нейросеть. Тогда все конъюнкции (ситуации) имеют одинаковое число высказываний. Если в этом случае две отличные друг от друга ситуации приводят к разным решениям, соответствующая нейросеть является совершенной. Привлекательность таких нейросетей заключается в их сводимости к однослойным. Если провести размножение решений (см. подразд. 5.2), то получим совершенную нейросеть (без обратных связей).
К построению совершенной нейросети можно свести задачу настоящего раздела, подразд. 6.2, а также, например, задачу оценки странового риска и др.
Заключение
Распределение величин возбуждения нейронов выходного слоя, а чаше всего нейрон, обладающий максимальной величиной возбуждения, позволяют установить соответствие между комбинацией и величинами возбуждений на входном слое (изображение на сетчатке глаза) и получаемым ответом (что это). Таким образом, эта зависимость и определяет возможность логического вывода вида "если -- то». Управление, формирование данной зависимости осуществляются весами синапсических связей нейронов, которые влияют на направления распространения возбуждения нейронов в сети, приводящие на этапе обучения к «нужным» нейронам выходного слоя. т.е. служат связыванию и запоминанию отношений «посылка -- следствие». Связь подструктур нейросети позволяет получать «длинные» логические цепочки на основе подобных отношений.
Отсюда следует, что сеть работает в двух режимах: в режиме обучения и в режиме распознавания (рабочем режиме).
В режиме обучения производится формирование логических цепочек.
В режиме распознавания нейросеть по предъявляемому образу с высокой достоверностью определяет, к какому типу он относится, какие действия следует предпринять и т.д.
Считается, что в человеческом мозге до 100 млрд нейронов. Но сейчас нас не интересует, как устроен нейрон, в котором насчитывают до 240 химических реакций. Нас интересует, работает нейрон на логическом уровне, как выполняет он логические функции. Реализация лишь этих функций должна стать основой и средством искусственного интеллекта. Воплощая эти логические функции, мы готовы нарушить основные законы физики, например закон сохранения энергии. Ведь мы рассчитываем не на физическое моделирование, а на доступное, универсальное -- компьютерное.
Итак, мы сосредоточиваем внимание на «(прямом» использовании нейросетей в задачах искусственного интеллекта. Однако их применение распространяется на решение и других задач. Для этого строят нейросетевые модели со структурой, ориентированной на данную задач), используют специальную систему связей нейроподобных элементов, определенный вил передаточной функции (часто используют так называемые сигмоилные связи, основанные на участии экспоненты при формировании передаточной функции), специально подобранные и динамически уточняемые веса. При этом используют свойства сходимости величин возбуждения нейронов, самооптимизации. При подаче входного вектора возбуждений через определенное число тактов работы нейросети значения возбуждения нейронов выходного слоя (в некоторых моделях все нейроны входного слоя являются нейронами выходного слоя и других нет) сходятся к неким величинам. Они могут указывать, например, на то, какой эталон в большей степени похож на «зашумленный». недостоверный входной образ, или на то. как найти решение некоторой задачи. Например, известная сеть Хопфилда . хоть и с ограничениями, может решать задачу коммивояжера - задачу экспоненциальной сложности. Сеть Хемминга успешно реализует ассоциативную память. Сети Кохонена (карты Кохонена) , добавлен 27.06.2011
Задача анализа деловой активности, факторы, влияющие на принятие решений. Современные информационные технологии и нейронные сети: принципы их работы. Исследование применения нейронных сетей в задачах прогнозирования финансовых ситуаций и принятия решений.
дипломная работа , добавлен 06.11.2011
Описание технологического процесса напуска бумаги. Конструкция бумагоделательной машины. Обоснование применения нейронных сетей в управлении формованием бумажного полотна. Математическая модель нейрона. Моделирование двух структур нейронных сетей.
курсовая работа , добавлен 15.10.2012
Способы применения технологий нейронных сетей в системах обнаружения вторжений. Экспертные системы обнаружения сетевых атак. Искусственные сети, генетические алгоритмы. Преимущества и недостатки систем обнаружения вторжений на основе нейронных сетей.
контрольная работа , добавлен 30.11.2015
Понятие искусственного интеллекта как свойства автоматических систем брать на себя отдельные функции интеллекта человека. Экспертные системы в области медицины. Различные подходы к построению систем искусственного интеллекта. Создание нейронных сетей.
презентация , добавлен 28.05.2015
Исследование задачи и перспектив использования нейронных сетей на радиально-базисных функциях для прогнозирования основных экономических показателей: валовый внутренний продукт, национальный доход Украины и индекс потребительских цен. Оценка результатов.
курсовая работа , добавлен 14.12.2014
Понятие и свойства искусственных нейронных сетей, их функциональное сходство с человеческим мозгом, принцип их работы, области использования. Экспертная система и надежность нейронных сетей. Модель искусственного нейрона с активационной функцией.
реферат , добавлен 16.03.2011
Сущность и функции искусственных нейронных сетей (ИНС), их классификация. Структурные элементы искусственного нейрона. Различия между ИНС и машинами с архитектурой фон Неймана. Построение и обучение данных сетей, области и перспективы их применения.
презентация , добавлен 14.10.2013
Применение нейрокомпьютеров на российском финансовом рынке. Прогнозирование временных рядов на основе нейросетевых методов обработки. Определение курсов облигаций и акций предприятий. Применение нейронных сетей к задачам анализа биржевой деятельности.
курсовая работа , добавлен 28.05.2009
История создания и основные направления в моделировании искусственного интеллекта. Проблемы обучения зрительному восприятию и распознаванию. Разработка элементов интеллекта роботов. Исследования в области нейронных сетей. Принцип обратной связи Винера.
Введение 3
Применение Data mining 5
Заключение 7
Литература 9
Введение
В последние несколько лет наблюдаем взрыв интереса к нейронным с етям , которые успешно применяются в самых различных областях - бизнесе, медицине, технике, геологии, физике. Нейронные сети вошли в практику везде, где нужно решать задачи прогнозирования, классификации или управления. Такой впечатляющий успех определяется несколькими причинами. Нейронные сети - исключительно мощный метод моделирования, позволяющий воспроизводить чрезвычайно сложные зависимости. В частности, нейронные сети нелинейны по своей природе. На протяжении многих лет линейное моделирование было основным методом моделирования в большинстве областей, поскольку для него хорошо разработаны процедуры оптимизации. В задачах, где линейная аппроксимация неудовлетворительна (а таких достаточно много), линейные модели работают плохо. Кроме того, нейронные сети справляются с задачами высокой размерности, которое не позволяет моделировать линейные зависимости в случае большого числа переменныхПростота в использовании. Нейронные сети учатся на примерах. Пользователь нейронной сети подбирает представительные данные, а затем запускает алгоритм обучения, который автоматически воспринимает структуру данных. При этом от пользователя, конечно, требуется какой-то набор эвристических знаний о том, как следует отбирать и подготавливать данные, выбирать нужную архитектуру сети и интерпретировать результаты, однако уровень знаний, необходимый для успешного применения нейронных сетей, гораздо скромнее, чем, например, при использовании традиционных методов статистики.
Нейронные сети привлекательны с интуитивной точки зрения, ибо они основаны на примитивной биологической модели нервных систем. В будущем развитие таких нейро-биологических моделей может привести к созданию действительно мыслящих компьютеров. Между тем уже «простые» нейронные с ети являются средством в инструментарии специалиста по прикладной статистике. Так, одни из наиболее мощных алгоритмов Data Mining основаны именно на нейронных сетях.
Data Mining переводится как «добыча» или «раскопка данных». Нередко рядом с Data Mining встречаются слова «обнаружение знаний в базах данных» и «интеллектуальный анализ данных». Их можно считать синонимами Data Mining. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных.
В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информации в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Что делать с этой информацией? Стало ясно, что без продуктивной переработки потоки сырых данных образуют никому не нужную свалку. Специфика современных требований к такой переработке следующие: данные имеют неограниченный объем, данные являются разнородными (количественными, качественными, текстовыми), результаты должны быть конкретны и понятны, инструменты для обработки сырых данных должны быть просты в использовании.
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом возникших проблем. Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез и для «грубого» разведочного анализа, составляющего основу оперативной аналитической обработки данных.
Важное положение Data Mining - нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания. К обществу пришло понимание, что сырые данные (raw data) содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки.
В целом технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро - один из основателей этого направления: Data Mining - это процесс обнаружения в сырых данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности
.
^
Применение Data mining
Сфера применения Data Mining ничем не ограничена - она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня, мягко говоря, заинтриговали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных. Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, известны сообщения об экономическом эффекте, в 10-70 раз превысившем первоначальные затраты от 350 до 750 тыс.$ Известны сведения о проекте в 20 млн. $, который окупился всего за 4 месяца. Другой пример - годовая экономия 700 тыс.$ за счет внедрения Data Mining в сети универсамов в Великобритании.
Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе. Кратко охарактеризуем некоторые возможные бизнес-приложения Data Mining.
^ Розничная торговля . Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.
исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа «Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку?»
создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
сегментация клиентов. Разбивая клиентов на различные категории, банки делают свою маркетинговую политику более целенаправленной и результативной, предлагая различные виды услуг разным группам клиентов.
прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями.
анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда в США крупная страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это новое знание пересмотром своей общей политики предоставления скидок семейным клиентам.
Заключение
Многие компании пытаются обрабатывать данные, сгенерированные при выполнении ежедневных операций. Вооружившись технологиями машинного обучения и визуализации можно среди беспорядочной информации обнаружить довольно ценные, хорошо интерпретируемые взаимосвязи. Приложения Data Mining, построенные на этих технологиях, успешно применяются в различных областях, в том числе в розничной торговле и маркетинге, позволяя компаниям добывать информацию, дающую конкурентные преимущества.Проблемы бизнес анализа формулируются по-иному, но решение большинства из них сводится к той или иной задаче Data Mining или к их комбинации. Например, оценка рисков – это решение задачи регрессии или классификации, сегментация рынка – кластеризация, стимулирование спроса – ассоциативные правила. Фактически, задачи Data Mining являются элементами, из которых можно собрать решение подавляющего большинства реальных бизнес задач.
Для решения вышеописанных задач используются различные методы и алгоритмы Data Mining. Ввиду того, что Data Mining развивалась и развивается на стыке таких дисциплин, как статистика, теория информации, машинное обучение, теория баз данных, вполне закономерно, что большинство алгоритмов и методов Data Mining были разработаны на основе различных методов из этих дисциплин. Большую популярность получили следующие методы Data Mining: нейронные сети, деревья решений, алгоритмы кластеризации, в том числе и масштабируемые, алгоритмы обнаружения ассоциативных связей между событиями и т.д.
Литература
Айвазян С. А., Бухштабер В. М., Юнюков И. С., Мешалкин Л. Д . Прикладная статистика: Классификация и снижение размерности. - М.: Финансы и статистика, 1989.
Knowledge Discovery Through Data Mining : What Is Knowledge Discovery? - Tandem Computers Inc., 1996.
Кречетов Н.. Продукты для интеллектуального анализа данных. - Рынок программных средств, N14-15_97, c. 32-39.
Boulding K. E. General Systems Theory - The Skeleton of Science//Management Science, 2, 1956.
Гик Дж., ван. Прикладная общая теория систем. - М.: Мир, 1981.
Киселев М., Соломатин Е.. Средства добычи знаний в бизнесе и финансах. - Открытые системы, № 4, 1997, с. 41-44.
Дюк В.А. Обработка данных на ПК в примерах. - СПб: Питер, 1997.
Рис. 13.12. Рис. 13.13. Рис. 13.14. Рис. 13.15. Рис. 13.16. Рис. 13.17. Рис. 13.18. Рис. 13.19. Рис. 13.20. Рис. 13.21. Рис. 13.22. Рис. 13.23. Рис. 13.24. Рис. 13.25. Рис. 13.26. Рис. 13.28. Общая технологическая схема обработки данных
Повседневная практика финансовых рынков находится в интересном противоречии с академической точкой зрения, согласно которой изменения цен финансовых активов происходят мгновенно, без каких-либо усилий эффективно отражая всю доступную информацию. Существование сотен маркет-мейкеров, трейдеров и фондовых менеджеров, работа которых состоит в том, чтобы делать прибыль, говорит о том, что участники рынка вносят определенный вклад в общую информацию. Более того, так как эта работа стоит дорого, то и объем привнесенной информации должен быть значительным.
Существование сотен маркет-мейкеров, трейдеров и фондовых менеджеров на финансовых рынках говорит о том, что все они обрабатывают финансовую информацию и принимают решения.
Труднее ответить на вопрос о том, как конкретно на финансовых рынках возникает и используется информация, которая может приносить прибыль. Исследования почти всегда показывают, что никакая устойчивая стратегия торговли не дает постоянной прибыли, и это, во всяком случае, так, если учитывать еще и расходы на совершение сделок. Хорошо известно также, что участники рынка (и весь рынок в целом) могут принимать совершенно различные решения исходя из сходной или даже неизменной информации.
Участники рынка в своей работе, по-видимому, не ограничиваются линейными состоятельными правилами принятия решений, а имеют в запасе несколько сценариев действий, и то, какой из них пускается в ход, зависит подчас от внешних незаметных признаков. Один из возможных подходов к многомерным и зачастую нелинейным информационным рядам финансового рынка заключается в том, чтобы по возможности подражать образцам поведения участников рынка, используя такие методы искусственного интеллекта, как экспертные системы или нейронные сети.
На моделирование процессов принятия решений этими методами было потрачено много усилий. Оказалось, однако, что экспертные системы в сложных ситуациях хорошо работают лишь тогда, когда системе присуща внутренняя стационарность (т.е. когда на каждый входной вектор имеется единственный не меняющийся со временем ответ). Под такое описание в какой-то степени подходят задачи комплексной классификации или распределения кредитов, но оно представляется совершенно неубедительным для финансовых рынков с их непрерывными структурными изменениями. В случае с финансовыми рынками едва ли можно утверждать, что можно достичь полного или хотя бы в определенной степени адекватного знания о данной предметной области, в то время как для экспертных систем с алгоритмами, основанными на правилах, это - обычное требование.
Нейронные сети предлагают совершенно новые многообещающие возможности для банков и других финансовых институтов, которым по роду своей деятельности приходится решать задачи в условиях небольших априорных знаний о среде. Характер финансовых рынков драматическим образом меняется с тех пор, как вследствие ослабления контроля, приватизации и появления новых финансовых инструментов национальные рынки слились в общемировые, а в большинстве секторов рынка возросла свобода финансовых операций. Очевидно, что сами основы управления риском и доходом не могли не претерпеть изменений, коль скоро возможности диверсификации и стратегии защиты от риска изменились до неузнаваемости.
Одной из сфер применения нейронных сетей для ряда ведущих банков стала проблема изменений позиции доллара США на валютном рынке при большом числе неизменных объективных показателей. Возможности такого применения облегчаются тем, что имеются огромные базы экономических данных, - ведь сложные модели всегда прожорливы в отношении информации.
Котировки облигаций и арбитраж - еще одна область, где задачи расширения и сужения риска, разницы в процентных ставках и ликвидности, глубины и ликвидности рынка являются благоприятным материалом для мощных вычислительных методов.
Еще одной проблемой, значение которой в последнее время возрастает, является моделирование потоков средств между институциональными инвесторами. Падение процентных ставок сыграло решающую роль в повышении привлекательности инвестиционных фондов открытого типа и индексных фондов, а наличие опционов и фьючерсов на их акции позволяет приобретать их с полной или частичной гарантией.
Очевидно, что задача оптимизации в условиях, когда число частичных ограничений равновесия бесконечно (например, на фьючерсном и наличном рынке любого товара в любом секторе рынка играют роль перекрестные разности процентных ставок), становится проблемой чрезвычайной сложности, все более выходящей за рамки возможностей любого трейдера.
В таких обстоятельствах трейдеры и, следовательно, любые системы, стремящиеся описать их поведение, в каждый момент времени должны будут сосредоточивать внимание на уменьшении размерности задачи. Хорошо известно такое явление, как ценная бумага повышенного спроса.
Когда речь идет о финансовом секторе, можно с уверенностью утверждать, что первые результаты, полученные при применении нейронных сетей, являются весьма обнадеживающими, и исследования в этой области нужно развивать. Как это уже было с экспертными системами, может потребоваться несколько лет, прежде чем финансовые институты достаточно уверятся в возможностях нейронных сетей и станут использовать их на полную мощность.
Характер разработок в области нейронных сетей принципиально отличается от экспертных систем: последние построены на утверждениях типа «если..., то...», которые нарабатываются в результате длительного процесса обучения системы, а прогресс достигается, главным образом, за счет более удачного использования формально-логических структур. В основе нейронных сетей лежит преимущественно-поведенческий подход к решаемой задаче: сеть «учится на примерах» и подстраивает свои параметры при помощи так называемых алгоритмов обучения через механизм обратной связи.
РАЗЛИЧНЫЕ ВИДЫ ИСКУССТВЕННЫХ НЕЙРОНОВ
Искусственным нейроном (рис. 13.1 ) называется простой элемент, сначала вычисляющий взвешенную сумму V входных величин формула" src="http://hi-edu.ru/e-books/xbook725/files/13.1.gif" border="0" align="absmiddle" alt="(13.1)
Здесь N- размерность пространства входных сигналов.
Затем полученная сумма сравнивается с пороговой величиной (или bias) формула" src="http://hi-edu.ru/e-books/xbook725/files/18.gif" border="0" align="absmiddle" alt=" во взвешенной сумме (1) обычно называют синаптическими коэффициентами или весами. Саму же взвешенную сумму V мы будем называть потенциалом нейрона i. Выходной сигнал тогда имеет вид f(V).
Величину порогового барьера можно рассматривать как еще один весовой коэффициент при постоянном входном сигнале. В этом случае мы говорим о расширенном входном пространстве : нейрон с N -мерным входом имеет N+1 весовой коэффициент..2.gif" border="0" align="absmiddle" alt="(13.2)
В зависимости от способа преобразования сигнала и характера функции активации возникают различные виды нейронных структур. Мы будем рассматривать только детерминированные нейроны (в противоположность вероятностным нейронам , состояние которых в момент t есть случайная функция потенциала и состояния в момент t-1). Далее, мы будем различать статические нейроны - такие, в которых сигнал передается без задержки,- и динамические , где учитывается возможность таких задержек, учитывается («синапсы с запаздыванием» ).
РАЗЛИЧНЫЕ ВИДЫ ФУНКЦИИ АКТИВАЦИИ
Функции активации f могут быть различных видов:
Формула" src="http://hi-edu.ru/e-books/xbook725/files/20.gif" border="0" align="absmiddle" alt=", крутизну b можно учесть через величины весов и порогов, и без ограничения общности можно полагать ее равной единице.
Возможно также определить нейроны без насыщения, принимающие на выходе непрерывное множество значений. В задачах классификации выходное значение может определяться порогом - при принятии единственного решения,- или быть вероятностным- при определении принадлежности к классу. Чтобы учесть особенности конкретной задачи, могут быть выбраны различные другие виды функции активации - гауссова, синусоидальная, всплески (wavelets) и т.д.
НЕЙРОННЫЕ СЕТИ С ПРЯМОЙ СВЯЗЬЮ
Мы будем рассматривать два вида нейронных сетей: статические, которые также часто называют сетями с прямой связью (feed-forward), и динамические, или рекуррентные сети. В этом разделе мы займемся Статическими сетями. Сети других видов будут кратко рассмотрены позднее.
Нейронные сети с прямой связью состоят из статических нейронов, так что сигнал на выходе сети появляется в тот же момент, когда подаются сигналы на вход. Организация (топология) сети может быть различной. Если не все составляющие ее нейроны являются выходными, говорят, что сеть содержит скрытые нейроны. Наиболее общий тип архитектуры сети получается в случае, когда все нейроны связаны друг с другом (но без обратных связей). В конкретных задачах нейроны обычно бывают сгруппированы в слои. На рис. 13.2 показана типовая схема нейронной сети с прямой связью с одним скрытым слоем.
Интересно отметить, что, согласно теоретическим результатам, нейронные сети с прямой связью и с сигмоидными функциями являются универсальным средством для приближения (аппроксимации) функций. Говоря точнее, любую вещественнозначную функцию нескольких переменных на компактной области определения можно сколь угодно точно приблизить с помощью трехслойной сети. При этом, правда, мы не знаем ни размеров сети, которая для этого потребуется, ни значений весов. Более того, из доказательства этих результатов видно, что число скрытых элементов неограниченно возрастает при увеличении точности приближения. Сети с прямой связью, действительно, могут служить универсальным средством для аппроксимации, но нет никакого правила, позволяющего найти оптимальную топологию сети для данной задачи.
Таким образом, задача построения нейронной сети является нетривиальной. Вопросы о том, сколько нужно взять скрытых слоев, сколько элементов в каждом из них, сколько связей и какие обучающие параметры, в имеющейся литературе, как правило, трактуются облегченно.
На этапе обучения происходит вычисление синаптических коэффициентов в процессе решения нейронной сетью задач (классификации, предсказания временных рядов и др.), в которых нужный ответ определяется не по правилам, а с помощью примеров, сгруппированных в обучающие множества . Такое множество состоит из ряда примеров с указанным для каждого из них значением выходного параметра, которое было бы желательно получить. Действия, которые при этом происходят, можно назвать контролируемым обучением : «учитель» подает на вход сети вектор исходных данных, а на выходной узел сообщает желаемое значение результата вычислений. Контролируемое обучение нейронной сети можно рассматривать как решение оптимизационной задачи. Ее целью является минимизация функции ошибок, или невязки, Е на данном множестве примеров путем выбора значений весов W.
КРИТЕРИИ ОШИБОК
Целью процедуры минимизации является отыскание глобального минимума - достижение его называется сходимостью процесса обучения. Поскольку невязка зависит от весов нелинейно, получить решение в аналитической форме невозможно, и поиск глобального минимума осуществляется посредством итерационного процесса - так называемого обучающего алгоритма , который исследует поверхность невязки и стремится обнаружить на ней точку глобального минимума. Обычно в качестве меры погрешности берется средняя квадратичная ошибка (MSE), которая определяется как сумма квадратов разностей между желаемой величиной выхода формула" src="http://hi-edu.ru/e-books/xbook725/files/22.gif" border="0" align="absmiddle" alt="для каждого примера к.
пример"> критерием максимума правдоподобия :
пример">«эпохи» ). Изменение весов происходит в направлении, обратном к направлению наибольшей крутизны для функции стоимости:
- определяемый пользователем параметр, который называется величиной градиентного шага или коэффициентом обучения .
Другой возможный метод носит название стохастического градиентного .
В нем веса пересчитываются после каждого просчета всех примеров из одного обучающего множества, и при этом используется частичная функция стоимости, соответствующая этому, например k-му, множеству:
подзаголовок">
ОБРАТНОЕ РАСПРОСТРАНЕНИЕ ОШИБКИ
Рассмотрим теперь наиболее распространенный алгоритм обучения нейронных сетей с прямой связью - алгоритм обратного распространения ошибки (Backpropagation, BP), представляющий собой развитие так называемого обобщенного дельта-правила . Этот алгоритм был заново открыт и популяризирован в 1986 г. Ру-мельхартом и МакКлеландом из знаменитой Группы по изучению параллельных распределенных процессов в Массачусетском технологическом институте. В этом пункте мы более подробно рассмотрим математическую суть алгоритма. Он является алгоритмом градиентного спуска, минимизирующим суммарную квадратичную ошибку:
формула" src="http://hi-edu.ru/e-books/xbook725/files/24.gif" border="0" align="absmiddle" alt=". Вычисление частных производных осуществляется по правилу цепи : вес входа j-го нейрона, идущего от j-гo нейрона, пересчитывается по формуле
формула" src="http://hi-edu.ru/e-books/xbook725/files/23.gif" border="0" align="absmiddle" alt="- длина шага в направлении, обратном к градиенту.
Если рассмотреть отдельно k-й образец, то соответствующее изменение весов равно
вычисляется через аналогичные множители из последующего слоя, и ошибка, таким образом, передается в обратном направлении.
Для выходных элементов мы получаем:
формула" src="http://hi-edu.ru/e-books/xbook725/files/25.gif" border="0" align="absmiddle" alt="определяется так:
формула" src="http://hi-edu.ru/e-books/xbook725/files/13.14.gif" border="0" align="absmiddle" alt="(13.14)
получаем:
пример">стохастическом варианте веса пересчитываются каждый раз после просчета очередного образца, а в «эпохальном», или off-line варианте, веса меняются после просчета всего обучающего множества.
Другой часто применяемый прием состоит в том, что при определении направления поиска к текущему градиенту добавляется поправка - вектор смещения предыдущего шага, взятый с некоторым коэффициентом. Можно сказать, что учитывается уже имеющийся импульс движения. Окончательная формула для изменения весов выглядит так:
формула" src="http://hi-edu.ru/e-books/xbook725/files/26.gif" border="0" align="absmiddle" alt="- число в интервале (0,1), которое задается пользователем.
Часто значением подзаголовок">
ДРУГИЕ АЛГОРИТМЫ ОБУЧЕНИЯ
Наконец, в последнее время пользуются успехом так называемые генетические алгоритмы , в которых набор весов рассматривается как индивид, подверженный мутациям и скрещиванию , а в качестве показателя его «качества» берется критерий ошибки. По мере того как нарождаются новые поколения, все более вероятным становится появление оптимального индивида.
В финансовых приложениях данные зашумлены особенно сильно. Например, совершение сделок может регистрироваться в базе данных с запозданием, причем в разных случаях- с разным. Пропуск значений или неполную информацию также иногда рассматривают как шум: в таких случаях берется среднее или наилучшее значение, и это, конечно, приводит к зашумлению базы данных. Отрицательно сказывается на обучении неправильное определение класса объекта в задачах распознавания - это ухудшает способность системы к обобщению при работе с новыми (т.е. не входившими в число образцов) объектами.
ПЕРЕКРЕСТНОЕ ПОДТВЕРЖДЕНИЕ
Для того чтобы устранить произвол в разбиении базы данных, могут быть применены методы повторных проб. Рассмотрим один из таких методов, который называется перекрестным подтверждением . Его идея состоит в том, чтобы случайным образом разбить базу данных на q попарно не пересекающихся подмножеств. Затем производится q обучений на (q -1) множестве, а ошибка вычисляется по оставшемуся множеству. Если q достаточно велико, например равно 10, каждое обучение задействует большую часть исходных данных. Если процедура обучения надежна, то результаты по q различным моделям должны быть очень близки друг к другу. После этого итоговая характеристика определяется как среднее всех полученных значений ошибки. К сожалению, при применении этого метода объем вычислений часто оказывается очень большим, так как требуется проделать q обучений, и в реальном приложении с большей размерностью это может быть невыполнимо. В предельном случае, когда q = Р, где Р - общее число примеров, метод называется перекрестным подтверждением с одним в остатке . Такой метод оценки имеет смещение, и разработан метод «складного ножа» , уменьшающий этот недостаток ценой еще большего объема вычислений.
Следующий класс нейронных сетей, который мы рассмотрим, - динамические или рекуррентные, сети. Они построены из динамических нейронов, чье поведение описывается дифференциальными или разностными уравнениями, как правило, первого порядка. Сеть организована так, что каждый нейрон получает входную информацию от других нейронов (возможно, и от себя самого) и из окружающей среды. Этот тип сетей имеет важное значение, так как с его помощью можно моделировать нелинейные динамические системы. Это - весьма общая модель, которую потенциально можно использовать в самых разных приложениях, например: ассоциативная память, нелинейная обработка сигналов, моделирование конечных автоматов, идентификация систем, задачи управления.
Нейронные сети с временной задержкой
Перед тем, как описать собственно динамические сети, рассмотрим, как сеть с прямой связью используется для обработки временных рядов. Метод состоит в том, чтобы разбить временной ряд на несколько отрезков и получить таким образом статистический образец для подачи на вход многослойной сети с прямой связью. Это осуществляется с помощью так называемой разветвленной линии задержки (см. рис. 13.3 ).
Архитектура такой нейронной сети с временной задержкой позволяет моделировать любую конечную временную зависимость вида:
подзаголовок">
СЕТИ ХОПФИЛДА
С помощью рекуррентных сетей Хопфилда можно обрабатывать неупорядоченные (рукописные буквы), упорядоченные во времени (временные ряды) или пространстве (графики, грамматики) образцы (рис. 13.4 ). Рекуррентная нейронная сеть простейшего вида введена Хопфилдом; она построена из N нейронов, связанных каждый с каждым, причем все нейроны являются выходными.
Сети такой конструкции используются, главным образом, в качестве ассоциативной памяти, а также в задачах нелинейной фильтрации данных и грамматического вывода. Кроме этого, недавно они были применены для предсказывания и для распознавания закономерностей в поведении цен акций.
Введенную Кохоненом «самоорганизующуюся карту признаков» можно рассматривать как вариант нейронной сети. Сеть такого типа рассчитана на самостоятельное обучение : во время обучения сообщать ей правильные ответы необязательно. В процессе обучения на вход сети подаются различные образцы. Сеть улавливает особенности их структуры и разделяет образцы на 436 кластеры, а уже полученная сеть относит каждый вновь поступающий пример к одному из кластеров, руководствуясь некоторым критерием «близости».
Сеть состоит из одного входного и одного выходного слоя. Количество элементов в выходном слое непосредственно определяет, сколько кластеров сеть может распознавать. Каждый из выходных элементов получает на вход весь входной вектор. Как и во всякой нейронной сети, каждой связи приписан некоторый синоптический вес. В большинстве случаев каждый выходной элемент соединен также со своими соседями. Эти внутренние связи играют важную роль в процессе обучения, так как корректировка весов происходит только в окрестности того элемента, который наилучшим образом откликается на очередной вход.
Выходные элементы соревнуются между собой за право вступить в действие и «получить урок». Выигрывает тот из них, чей вектор весов окажется ближе всех к входному вектору в смысле расстояния, определяемого, например, евклидовой метрикой. У элемента-победителя это расстояние будет меньше, чем у всех остальных. На текущем шаге обучения менять веса разрешается только элементу-победителю (и, может быть, его непосредственным соседям); веса остальных элементов при этом как бы заморожены. Выигравший элемент заменяет свой весовой вектор, немного перемещая его в сторону входного вектора. После обучения на достаточном количестве примеров совокупность весовых векторов с большей точностью приходит в соответствие со структурой входных примеров - векторы весов в буквальном смысле моделируют распределение входных образцов.

Рис. 13.5. Самоорганизующаяся сеть Кохонена. Изображены только связи, идущие в i-й узел. Окрестность узла показана пунктиром
Очевидно, для правильного понимания сетью входного распределения нужно, чтобы каждый элемент сети становился победителем одинаковое число раз - весовые векторы должны быть равновероятными .
Перед началом работы сети Кохонена нужно сделать две вещи:
векторы величины должны быть случайно распределены по единичной сфере;
все весовые и входные векторы должны быть нормированы на единицу.
Сеть со встречным распространением (CPN, Counterpropagation Network) соединяет в себе свойства самоорганизующейся сети Кохонена и концепцию Oustar - сети Гроссберга. В рамках этой архитектуры элементы слоя сети Кохонена не имеет прямого выхода во внешний мир, а служат входами для выходного слоя, в котором связям адаптивно придаются веса Гроссберга. Эта схема возникла из работ Хехта - Нильсена. CPN-сеть нацелена на постепенное построение искомого отображения входов в выходы на основе примеров действия такого отображения. Сеть хорошо решает задачи, где требуется способность адаптивно строить математическое отражение по его точным значениям в отдельных точках.
Сети данного вида успешно применяются в таких финансовых и экономических приложениях, как рассмотрение заявок на предоставление займов, предсказание трендов цен акций, товаров и курсов обмена валют. Говоря обобщенно, можно ожидать успешного применения CPN-сетей в задачах, где требуется извлекать знания из больших объемов данных.
ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ЗАДАЧ КЛАССИФИКАЦИИ (КЛАСТЕРИЗАЦИИ)
Решение задачи классификации является одним из важнейших применений нейронных сетей. Задача классификации представляет собой задачу отнесения образца к одному из нескольких попарно непересекающихся множеств. Примером таких задач может быть, например, задача определения кредитоспособности клиента банка, медицинские задачи, в которых необходимо определить, например, исход заболевания, решение задач управления портфелем ценных бумаг (продать, купить или «придержать» акции в зависимости от ситуации на рынке), задача определения жизнеспособных и склонных к банкротству фирм.
ЦЕЛЬ КЛАССИФИКАЦИИ
При решении задач классификации необходимо отнести имеющиеся статические образцы (характеристики ситуации на рынке, данные медосмотра, информация о клиенте) к определенным классам . Возможны несколько способов представления данных. Наиболее распространенным является способ, при котором образец представляется вектором. Компоненты этого вектора представляют собой различные характеристики образца, которые влияют на принятие решения о том, к какому классу можно отнести данный образец. Например, для медицинских задач в качестве компонентов этого вектора могут быть данные из медицинской карты больного. Таким образом, на основании некоторой информации о примере, необходимо определить, к какому классу его можно отнести. Классификатор таким образом относит объект к одному из классов в соответствии с определенным разбиением N-мерного пространства, которое называется пространством входов , и размерность этого пространства является количеством компонент вектора.
Прежде всего, нужно определить уровень сложности системы. В реальных задачах часто возникает ситуация, когда количество образцов ограниченно, что осложняет определение сложности задачи. Возможно выделить три основных уровня сложности. Первый (самый простой) - когда классы можно разделить прямыми линиями (или гиперплоскостями, если пространство входов имеет размерность больше двух) - так называемая линейная разделимость . Во втором случае классы невозможно разделить линиями (плоскостями), но их возможно отделить с помощью более сложного деления - нелинейная разделимость . В третьем случае классы пересекаются, и можно говорить только о вероятностной разделимости .

Рис. 13.6. Линейно и нелинейно разделимые классы
В идеальном варианте после предварительной обработки мы должны получить линейно разделимую задачу, так как после этого значительно упрощается построение классификатора. К сожалению, при решении реальных задач мы имеем ограниченное количество образцов, на основании которых и производится построение классификатора. При этом мы не можем провести такую предобработку данных, при которой будет достигнута линейная разделимость образцов.
ИСПОЛЬЗОВАНИЕ НЕЙРОННЫХ СЕТЕЙ В КАЧЕСТВЕ КЛАССИФИКАТОРА
Сети с прямой связью являются универсальным средством аппроксимации функций, что позволяет их использовать в решении задач классификации. Как правило, нейронные сети оказываются наиболее эффективным способом классификации, потому что генерируют фактически большое число регрессионных моделей (которые используются в решении задач классификации статистическими методами).
К сожалению, в применении нейронных сетей в практических задачах возникает ряд проблем. Во-первых, заранее неизвестно, какой сложности (размера) может потребоваться сеть для достаточно точной реализации отображения. Эта сложность может оказаться чрезмерно высокой, что потребует сложной архитектуры сетей. Так, Минский в своей работе «Персептроны» доказал, что простейшие однослойные нейронные сети способны решать только линейно разделимые задачи. Это ограничение преодолимо при использовании многослойных нейронных сетей. В общем виде можно сказать, что в сети с одним скрытым слоем вектор, соответствующий входному образцу, преобразуется скрытым слоем в некоторое новое пространство, которое может иметь другую размерность, а затем гиперплоскости, соответствующие нейронам выходного слоя, разделяют его на классы. Таким образом сеть распознает не только характеристики исходных данных, но и «характеристики характеристик», сформированные скрытым слоем.
ПОДГОТОВКА ИСХОДНЫХ ДАННЫХ
Для построения классификатора необходимо определить, какие параметры влияют на принятие решения о том, к какому классу принадлежит образец. При этом могут возникнуть две проблемы. Во-первых, если количество параметров мало, то может возникнуть ситуация, при которой один и тот же набор исходных данных соответствует примерам, находящимся в разных классах. Тогда невозможно обучить нейронную сеть, и система не будет корректно работать (невозможно найти минимум, который соответствует такому набору исходных данных). Исходные данные обязательно должны быть непротиворечивы. Для решения этой проблемы необходимо увеличить размерность пространства признаков (количество компонент входного вектора, соответствующего образцу). Но при увеличении размерности пространства признаков может возникнуть ситуация, когда число примеров может стать недостаточным для обучения сети, и она вместо обобщения просто запомнит примеры из обучающей выборки и не сможет корректно функционировать. Таким образом, при определении признаков необходимо найти компромисс с их количеством.
Далее необходимо определить способ представления входных данных для нейронной сети, т.е. определить способ нормирования. Нормировка необходима, поскольку нейронные сети работают с данными, представленными числами в диапазоне 0..1, а исходные данные могут иметь произвольный диапазон или вообще быть нечисловыми данными. При этом возможны различные способы, начиная от простого линейного преобразования в требуемый диапазон и заканчивая многомерным анализом параметров и нелинейной нормировкой в зависимости от влияния параметров друг на друга.
КОДИРОВАНИЕ ВЫХОДНЫХ ЗНАЧЕНИЙ
Задача классификации при наличии двух классов может быть решена на сети с одним нейроном в выходном слое, который может принимать одно из двух значений 0 или 1 в зависимости от того, к какому классу принад-440 лежит образец. При наличии нескольких классов возникает проблема, связанная с представлением этих данных для выхода сети. Наиболее простым способом представления выходных данных в таком случае является вектор, компоненты которого соответствуют различным номерам классов. При этом i-я компонента вектора соответствует i-му классу. Все остальные компоненты при этом устанавливаются в 0. Тогда, например, второму классу будет соответствовать 1 на 2 выходе сети и 0 на остальных. При интерпретации результата обычно считается, что номер класса определяется номером выхода сети, на котором появилось максимальное значение. Например, если в сети с тремя выходами, мы имеем вектор выходных значений (0,2; 0,6; 0,4), и видим, что максимальное значение имеет вторая компонента вектора, значит класс, к которому относится этот пример, - 2. При таком способе кодирования иногда вводится также понятие уверенности сети в том, что пример относится к этому классу. Наиболее простой способ определения уверенности заключается в определении разности между максимальным значением выхода и значением другого выхода, которое является ближайшим к максимальному. Например, для рассмотренного выше примера уверенность сети в том, что пример относится ко второму классу, определится как разность между второй и третьей компонентой вектора и равна 0.6-0.4=0.2. Соответственно, чем выше уверенность, тем больше вероятность того, что сеть дала правильный ответ. Этот метод кодирования является самым простым, но не всегда самым оптимальным способом представления данных.
Известны и другие способы. Например, выходной вектор представляет собой номер кластера, записанный в двоичной форме. Тогда при наличии 8 классов нам потребуется вектор из 3 элементов, и, скажем, 3 классу будет соответствовать вектор 011. Но при этом в случае получения неверного значения на одном из выходов мы можем получить неверную классификацию (неверный номер кластера), поэтому имеет смысл увеличить расстояние между двумя кластерами за счет использования кодирования выхода по коду Хемминга, который повысит надежность классификации.
Другой подход состоит в разбиении задачи с к классами на k*(k-l)/2 подзадач с двумя классами (2 на 2 кодирование) каждая. Под подзадачей в данном случае понимается то, что сеть определяет наличие одной из компонент вектора. Т.е. исходный вектор разбивается на группы по два компонента в каждой таким образом, чтобы в них вошли все возможные комбинации компонент выходного вектора. Число этих групп можно определить как количество неупорядоченных выборок по два из исходных компонент.
352" border="0">
Где 1 на выходе говорит о наличии одной из компонент. Тогда мы можем перейти к номеру класса по результату расчета сетью следующим образом: определяем, какие комбинации получили единичное (точнее близкое к единице) значение выхода (т.е. какие подзадачи у нас активировались), и считаем, что номер класса будет тот, который вошел в наибольшее количество активированных подзадач (см. таблицу).
Документ без названия
Это кодирование во многих задачах дает лучший результат, чем классический способ кодирования.
ВЕРОЯТНОСТНАЯ КЛАССИФИКАЦИЯ
При статистическом распознавании образов оптимальный классификатор относит образец формула" src="http://hi-edu.ru/e-books/xbook725/files/1.gif" border="0" align="absmiddle" alt="
отнести формула" src="http://hi-edu.ru/e-books/xbook725/files/4.gif" border="0" align="absmiddle" alt="относится к группе, имеющей наибольшую апостериорную вероятность. Это правило оптимально в том смысле, что оно минимизирует среднее число неправильных классификаций..gif" border="0" align="absmiddle" alt="
то байесовское соотношение между априорной и апостериорной вероятностью сохраняет силу, и поэтому эти функции можно использовать в качестве упрощенных решающих функций . Так имеет смысл делать, если эти функции строятся и вычисляются более просто.
Хотя правило выглядит очень простым, применить его на практике оказывается трудно, так как бывают неизвестны апостериорные вероятности (или даже значения упрощенных решающих функций). Их значения можно оценить. В силу теоремы Байеса апостериорные вероятности можно выразить через априорные вероятности и функции плотности по формуле формула" src="http://hi-edu.ru/e-books/xbook725/files/8.gif" border="0" align="absmiddle" alt=".
КЛАССИФИКАТОРЫ ОБРАЗОВ
Априорную плотность вероятности можно оценить различными способами. В параметрических методах предполагается, что плотность вероятности (PDF) является функцией определенного вида с неизвестными параметрами. Например, можно попробовать приблизить PDF при помощи гауссовой функции. Для того чтобы произвести классификацию, нужно предварительно получить оценочные значения для вектора среднего и матрицы ковариаций по каждому из классов данных и затем использовать их в решающем правиле. В результате получится полиномиальное решающее правило, содержащее только квадраты и попарные произведения переменных. Вся описанная процедура называется квадратичным дискриминантным анализом (QDA). В предположении, что матрицы ковариаций у всех классов одинаковы, QDA сводится к линейному дискриминантному анализу (LDA).
В методах другого типа - непараметрических - никаких предварительных предположений о плотности вероятности не требуется. В методе «к ближайших соседей» (NN) вычисляется расстояние между вновь поступившим образцом и векторами обучающего множества, после чего образец относится к тому классу, к которому принадлежит большинство из к его ближайших соседей. В результате этого границы, разделяющие классы, получаются кусочно линейными. В различных модификациях этого метода используются различные меры расстояния и специальные приемы нахождения соседей. Иногда вместо самого множества образцов берется совокупность центроидов, соответствующих кластерам в методе адаптивного векторного квантования (LVQ).
В других методах классификатор разбивает данные на группы по схеме дерева. На каждом шаге подгруппа разбивается надвое, и в результате получается иерархическая структура бинарного дерева. Разделяющие границы получаются, как правило, кусочно линейными и соответствуют классам, состоящим из одного или нескольких листьев дерева. Этот метод хорош тем, что он порождает метод классификации, основанный на логических решающих правилах. Идеи древовидных классификаторов применяются в методах построения самонаращивающихся нейронных классификаторов.
НЕЙРОННАЯ СЕТЬ С ПРЯМОЙ СВЯЗЬЮ КАК КЛАССИФИКАТОР
Поскольку сети с прямой связью являются универсальным средством аппроксимации функций, с их помощью можно оценить апостериорные вероятности в данной задаче классификации. Благодаря гибкости в построении отображения можно добиться такой точности аппроксимации апостериорных вероятностей, что они практически будут совпадать со значениями, вычисленными по правилу Байеса (так называемые оптимальные процедуры классификации.
ЗАДАЧА АНАЛИЗА ВРЕМЕННЫХ РЯДОВ
Временной ряд - это упорядоченная последовательность вещественных чисел формула" src="http://hi-edu.ru/e-books/xbook725/files/10.gif" border="0" align="absmiddle" alt="в n-мерном пространстве сдвинутых во времени значений, или пространстве задержки.
Цель анализа временных рядов - извлечь из данного ряда полезную информацию. Для этого необходимо построить математическую модель явления. Такая модель должна объяснять существо процесса, порождающего данные, в частности- описывать характер данных (случайные, имеющие тренд, периодические, стационарные и т.п.). После этого можно применять различные методы фильтрации данных (сглаживание, удаление выбросов и др.) с конечной целью - предсказать будущие значения.
Таким образом, этот подход основан на предположении, что временной ряд имеет некоторую математическую структуру (которая, например, может быть следствием физической сути явления). Эта структура существует в так называемом фазовом пространстве , координаты которого - это независимые переменные, описывающие состояние динамической системы. Поэтому первая задача, с которой придется столкнуться при моделировании - это подходящим образом определить фазовое пространство. Для этого нужно выбрать некоторые характеристики системы в качестве фазовых переменных. После этого уже можно ставить вопрос о предсказании или экстраполяции. Как правило, во временных рядах, полученных в результате измерений, в разной пропорции присутствуют случайные флуктуации и шум. Поэтому качество модели во многом определяется ее способностью аппроксимировать предполагаемую структуру данных, отделяя ее от шума.
СТАТИСТИЧЕСКИЙ АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
Подробное описание методов статистического анализа временных рядов выходит за рамки этой книги. Мы вкратце рассмотрим традиционные подходы, выделяя при этом обстоятельства, которые имеют прямое отношение к предмету нашего изложения. Начиная с пионерской работы Юла, центральное место в статистическом анализе временных рядов заняли линейные модели ARIMA. Со временем эта область оформилась в законченную теорию с набором методов - теорию Бокса-Дженкинса.
Присутствие в модели ARIMA авторегрессионного члена выражает то обстоятельство, что текущие значения переменной зависят от ее прошлых значений. Такие модели называются одномерными. Часто, однако, значения исследуемой целевой переменной связаны с несколькими разными временными рядами.

Рис. 13.7. Реализация ARIMA (p,q) модели на простейшей нейронной сети
Так будет, например, если целевая переменная - курс обмена валют, а другие участвующие переменные - процентные ставки (в каждой из двух валют).
Соответствующие методы называются многомерными . Математическая структура линейных моделей довольно проста, и расчеты по ним могут быть без особых трудностей выполнены с помощью стандартных пакетов численных методов. Следующим шагом в анализе временных рядов стала разработка моделей, способных учитывать нелинейности, присутствующие, как правило, в реальных процессах и системах. Одна из первых таких моделей была предложена Тонгом и называется пороговой авторегрессионной моделью (TAR).
В ней, при достижении определенных (установленных заранее) пороговых значений, происходит переключение с одной линейной AR-модели на другую. Тем самым в системе выделяется несколько режимов работы.
Затем предложены STAR-, или «гладкие» TAR-модели. Такая модель представляет собой линейную комбинацию нескольких моделей, взятых с коэффициентами, которые являются непрерывными функциями времени.
МОДЕЛИ, ОСНОВАННЫЕ НА НЕЙРОННЫХ СЕТЯХ С ПРЯМОЙ СВЯЗЬЮ
Любопытно заметить, что все описанные в предыдущем пункте модели могут быть реализованы посредством нейронных сетей. Любая зависимость вида
выделение">рис. 13.8
Действия на первом этапе- этапе предварительной обработки данных - очевидно, сильно зависят от специфики задачи. Нужно правильно выбрать число и вид показателей, характеризующих процесс, в том числе, - структуру задержек. После этого надо выбрать топологию сети. Если применяются сети с прямой связью, нужно определить число скрытых элементов. Далее, для нахождения параметров модели нужно выбрать критерий ошибки и оптимизирующий (обучающий) алгоритм. Затем, используя средства диагностики, следует проверить различные свойства модели. Наконец, нужно проинтерпретировать выходную информацию сети и, может быть, подать ее на вход какой-то другой системы поддержки принятия решений. Далее мы рассмотрим вопросы, которые приходится решать на этапах предварительной обработки, оптимизации и анализа (доводки ) сети.
СБОР ДАННЫХ
Самое важное решение, которое должен принять аналитик, - это выбор совокупности переменных для описания моделируемого процесса. Чтобы представить себе возможные связи между разными переменными, нужно хорошо понимать существо задачи. В этой связи очень полезно будет побеседовать с опытным специалистом в данной предметной области. Относительно выбранных вами переменных нужно понимать, значимы ли они сами по себе, или же в них всего лишь отражаются другие, действительно существенные переменные. Проверка на значимость включает в себя кросс-корреляционный анализ. С его помощью можно, например, выявить временную связь типа запаздывания (лаг) между двумя рядами. То, насколько явление может быть описано линейной моделью, проверяется с помощью регрессии по методу наименьших квадратов (OLS).
Полученная после оптимизации невязка подзаголовок">
НЕЙРОННЫЕ СЕТИ КАК СРЕДСТВО ДОБЫЧИ ДАННЫХ
Иногда возникает задача анализа данных, которые с трудом можно представить в математической числовой форме. Это случай, когда нужно извлечь данные, принципы отбора которых заданы нечетко: выделить надежных партнеров, определить перспективный товар и т.п. Рассмотрим типичную для задач подобного рода ситуацию - предсказание банкротств. Предположим, что у нас есть информация о деятельности нескольких десятков банков (их открытая финансовая отчетность) за некоторый период времени. По окончании этого периода мы знаем, какие из этих банков обанкротились, у каких отозвали лицензию, а какие продолжают стабильно работать (на момент окончания периода). И теперь нам необходимо решить вопрос, в каком из банков стоит размещать средства. Естественно, маловероятно, что мы хотим разместить средства в банке, который может скоро обанкротиться. Значит, нам надо каким-то образом решить задачу анализа рисков вложений в различные коммерческие структуры.
На первый взгляд, решить эту проблему несложно - ведь у нас есть данные о работе банков и результатах их деятельности. Но, на самом деле, эта задача не так проста. Возникает проблема, связанная с тем, что имеющиеся у нас данные описывают прошедший период, а нас интересует то, что будет в дальнейшем. Таким образом, нам надо на основании имеющихся у нас априорных данных получить прогноз на дальнейший период. Для решения этой задачи можно использовать различные методы.
Так, наиболее очевидным является применение методов математической статистики. Но тут возникает проблема с количеством данных, ибо статистические методы хорошо работают при большом объеме априорных данных, а у нас может быть ограниченное их количество. При этом статистические методы не могут гарантировать успешный результат.
Другим путем решения этой задачи может быть применение нейронных сетей, которые можно обучить на имеющемся наборе данных. В этом случае в качестве исходной информации используются данные финансовых отчетов различных банков, а в качестве целевого поля - итог их деятельности. Но при использовании описанных выше методов мы навязываем результат, не пытаясь найти закономерности в исходных данных. В принципе, все обанкротившиеся банки похожи друг на друга хотя бы тем, что они обанкротились. Значит, в их деятельности должно быть что-то более общее, что привело их к этому итогу, и можно попытаться найти эти закономерности с тем, чтобы использовать их в дальнейшем. И тут перед нами возникает вопрос о том, как найти эти закономерности. Для этого, если мы будем использовать методы статистики, нам надо определить, какие критерии «похожести» нам использовать, что может потребовать от нас каких-либо дополнительных знаний о характере задачи.
Однако существует метод, позволяющий автоматизировать все эти действия по поиску закономерностей - метод анализа с использованием самоорганизующихся карт Кохонена. Рассмотрим, как решаются такие задачи и как карты Кохонена находят закономерности в исходных данных. Для общности рассмотрения будем использовать термин объект (например, объектом может быть банк, как в рассмотренном выше примере, но описываемая методика без изменений подходит для решения и других задач - например, анализа кредитоспособности клиента, поиска оптимальной стратегии поведения на рынке и т.д.). Каждый объект характеризуется набором различных параметров , которые описывают его состояние. Например, для нашего примера параметрами будут данные из финансовых отчетов. Эти параметры часто имеют числовую форму или могут быть приведены к ней. Таким образом, нам надо на основании анализа параметров объектов выделить схожие объекты и представить результат в форме, удобной для восприятия.
Все эти задачи решаются самоорганизующимися картами Кохонена. Рассмотрим подробнее, как они работают. Для упрощения рассмотрения будем считать, что объекты имеют 3 признака (на самом деле их может быть любое количество).
Теперь представим, что все эти три параметра объектов представляют собой их координаты в трехмерном пространстве (в том самом пространстве, которое окружает нас в повседневной жизни). Тогда каждый объект можно представить в виде точки в этом пространстве, что мы и сделаем (чтобы у нас не было проблем с различным масштабом по осям, пронумеруем все эти признаки в интервал любым подходящим способом), в результате чего все точки попадут в куб единичного размера рис. 13.9 . Отобразим эти точки. Взглянув на этот рисунок, мы можем увидеть, как расположены объекты в пространстве, причем легко заметить участки, где объекты группируются, т.е. у них схожи параметры, значит и сами эти объекты, скорее всего, принадлежат одной группе. Нам надо найти способ, которым можно преобразовать данную систему в простую для восприятия, желательно двумерную систему (потому что уже трехмерную картинку невозможно корректно отобразить на плоскости) так, чтобы соседние в искомом пространстве объекты оказались рядом и на полученной картинке. Для этого используем самоорганизующуюся карту Кохонена. В первом приближении ее можно представить в виде сети, изготовленной из резины рис. 13.10 .
Мы, предварительно «скомкав», бросаем эту сеть в пространство признаков, где у нас уже имеются объекты, и далее поступаем следующим образом: берем один объект (точку в этом пространстве) и находим ближайший к нему узел сети. После этого этот узел подтягивается к объекту (т.к. сетка «резиновая», то вместе с этим узлом так же, но с меньшей силой подтягиваются и соседние узлы).
Затем выбирается другой объект (точка), и процедура повторяется. В результате мы получим карту, расположение узлов которой совпадает с расположением основных скоплений объектов в исходном пространстве рис.13.11 . Кроме того, полученная карта обладает следующим замечательным свойством - узлы ее расположились таким образом, что объектам, похожим между собой соответствуют соседние узлы карты. Теперь определяем, какие объекты у нас попали в какие узлы карты. Это также определяется ближайшим узлом - объект попадает в тот узел, который находится ближе к нему. В результате всех этих операций объекты со схожими параметрами попадут в один узел или в соседние узлы. Таким образом, можно считать, что мы смогли решить задачу поиска похожих объектов и их группировки.
Но на этом возможности карт Кохонена не заканчиваются. Они позволяют также представить полученную информацию в простой и наглядной форме путем нанесения раскраски. Для этого мы раскрашиваем полученную карту (точнее, ее узлы) цветами, соответствующими интересующим нас признакам объектов. Возвращаясь к примеру с классификацией банков, можно раскрасить одним цветом те узлы, куда попал хоть один из банков, у которых была отозвана лицензия. Тогда после нанесения раскраски мы получим зону, которую можно назвать зоной риска, и попадание интересующего нас банка в эту зону говорит о его ненадежности.
Но и это еще не все. Мы можем также получить информацию о зависимостях между параметрами. Нанеся на карту раскраску, соответствующую различным статьям отчетов, можно получить так называемый атлас, хранящий в себе информацию о состоянии рынка. При анализе, сравнивая расположение цветов на раскрасках, порожденных различными параметрами, можно получить полную информацию о финансовом портрете банков - неудачников, процветающих банков и т.д.
При всем этом описанная технология является универсальным методом анализа. С ее помощью можно анализировать различные стратегии деятельности, производить анализ результатов маркетинговых исследований, проверять кредитоспособность клиентов и т.д.
Имея перед собой карту и зная информацию о некоторых из исследуемых объектов, мы можем достаточно достоверно судить об объектах, с которыми мы мало знакомы. Нужно узнать, что из себя представляет новый партнер? Отобразим его на карте и посмотрим на соседей. В результате, можно извлекать информацию из базы данных, основываясь на нечетких характеристиках.
ОЧИСТКА И ПРЕОБРАЗОВАНИЕ БАЗЫ ДАННЫХ
Предварительное, до подачи на вход сети, преобразование данных с помощью стандартных статистических приемов может существенно улучшить как параметры обучения (длительность, сложность), так и работу системы. Например, если входной ряд имеет отчетливый экспоненциальный вид, то после его логарифмирования получится более простой ряд, и если в нем имеются сложные зависимости высоких порядков, обнаружить их теперь будет гораздо легче. Очень часто ненормально распределенные данные предварительно подвергают нелинейному преобразованию: исходный ряд значений переменной преобразуется некоторой функцией, и ряд, полученный на выходе, принимается за новую входную переменную. Типичные способы преобразования - возведение в степень, извлечение корня, взятие обратных величин, экспонент или логарифмов.
Для того чтобы улучшить информационную структуру данных, могут оказаться полезными определенные комбинации переменных - произведения, частные и т.д. Например, когда вы пытаетесь предсказать изменения цен акций по данным о позициях на рынке опционов, отношение числа опционов пут (put options, т.е. опционов на продажу) к числу опционов колл (call options, т.е. опционов на покупку) более информативно, чем оба этих показателя в отдельности. К тому же, с помощью таких промежуточных комбинаций часто можно получить более простую модель, что особенно важно, когда число степеней свободы ограниченно.
Наконец, для некоторых функций преобразования, реализованных в выходном узле, возникают проблемы с масштабированием. Сигмоид определен на отрезке , поэтому выходную переменную нужно масштабировать так, чтобы она принимала значения в этом интервале. Известно несколько способов масштабирования: сдвиг на константу, пропорциональное изменение значений с новым минимумом и максимумом, центрирование путем вычитания среднего значения, приведение стандартного отклонения к единице, стандартизация (два последних действия вместе). Имеет смысл сделать так, чтобы значения всех входных и выходных величин в сети всегда лежали, например, в интервале (или [-1,1]), - тогда можно будет без риска использовать любые функции преобразования.
ПОСТРОЕНИЕ МОДЕЛИ
Значения целевого ряда (это тот ряд, который нужно найти, например, доход по акциям на день вперед) зависят от N факторов, среди которых могут быть комбинации переменных, прошлые значения целевой переменной, закодированные качественные показатели.
Оценка качества модели обычно основывается на критерии согласия типа средней квадратичной ошибки (MSE) или квадратного корня из нее (RMSE). Эти критерии показывают, насколько предсказанные значения оказались близки к обучающему, подтверждающему или тестовому множествам.
В линейном анализе временных рядов можно получить несмещенную оценку способности к обобщению, исследуя результаты работы на обучающем множестве (MSE), число свободных параметров (W) и объем обучающего множества (N). Оценки такого типа называются информационными критериями (1С) и включают в себя компоненту, соответствующую критерию согласия, и компоненту штрафа, которая учитывает сложность модели. Были предложены следующие информационные критерии: нормализованный (NAIC), нормализованный байесовский (NBIC) и итоговая ошибка прогноза (FPE):
подзаголовок">
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
К настоящему времени разработано много программных пакетов, реализующих нейронные сети. Вот некоторые, наиболее известные: программы-симуляторы нейронных сетей, представленные на рынке программного обеспечения: Nestor, Cascade Correlation, Neudisk, Mimenice, Nu Web, Brain, Dana, Neuralworks Professional II Plus, Brain Maker, HNet, Explorer, Explorenet 3000, Neuro Solutions, Prapagator, Matlab Toolbox. Стоит также сказать о си-муляторах, свободно распространяемых через университетские серверы (например, SNNS (Штутгарт) или Nevada QuickPropagation). Важным качеством пакета является его совместимость с другими программами, задействованными в обработке данных. Кроме того, важны дружественный интерфейс и производительность, которая может доходить до многих мегафлопсов (млн. операций с плавающей точкой в секунду). Платы-ускорители позволяют сократить время обучения при работе на обычных персональных компьютерах. Однако для получения надежных результатов с помощью нейронных сетей, как правило, требуется мощный компьютер.
Устоявшиеся парадигмы финансовой науки такие, как модель случайного блуждания и гипотеза эффективного рынка, предполагают, что финансовые рынки реагируют на информацию рационально и плавно. В этом случае едва ли можно придумать что-то лучше линейных связей и стационарного поведения с обратимым трендом. К сожалению, в реальном поведении финансовых рынков мы видим не просто обратимость трендов, но постоянно возникающие несоответствия курсов, волатильность, явно не отвечающую поступающей информации, и периодически случающиеся скачки уровня цен и волатильности. Для описания поведения финансовых рынков были разработаны и имели определенный успех некоторые новые модели.
ФИНАНСОВЫЙ АНАЛИЗ НА РЫНКЕ ЦЕННЫХ БУМАГ
Финансовый анализ на рынке ценных бумаг с использованием нейросетевых технологий в данной работе проводится относительно торговли нефтью и нефтепродуктами.
Макроэкономический рост и благосостояние страны в огромной мере зависят от уровня развития базовых отраслей, среди которых исключительно важную роль играют нефтедобывающая и нефтеперерабатывающая промышленность. Ситуация в нефтяной отрасли в значительной степени определяет состояние всей экономики России. В связи со сложившейся конъюнктурой цен на мировом рынке нефти, для России наиболее доходной стороной в деятельности нефтяной отрасли, является экспорт. Экспорт нефти - один из важнейших и быстрых источников валютных поступлений. Одним из лучших представителей нефтяной промышленности является нефтяная компания «ЛУКОЙЛ». НК «ЛУКОЙЛ» является ведущей в России вертикально-интегрированной нефтяной компанией, которая специализируется на добыче и переработке нефти, производстве и сбыте нефтепродуктов. Компания работает не только в России, но и за рубежом, активно участвуя в перспективных проектах.
Финансово-производственная деятельность компании описана в таблице 13.1.
Таблица. 13.1
Основные финансовые и производственные показатели за 1998 год
Документ без названия
| Добыча нефти (включая газовый конденсат) | 64192 1284 |
|
| Коммерческая добыча газа | млн. куб. м/год млн. куб. футов/сутки | 3748 369 |
| Переработка нефти (собственные НПЗ, включая зарубежные) | тыс. тонн/год тыс. бар./сутки | 17947 359 |
| Экспорт нефти | тыс. тонн/год | 24711 |
| Экспорт нефтепродуктов | тыс. тонн/год | 3426 |
| Выручка-нетто от реализации | млн. рублей USD млн.* | 81660 8393 |
| Прибыль от реализации | млн. рублей USD млн.* | 5032 517 |
| Прибыль до налогообложения (по отчету) | млн. рублей USD млн.* | 2032 209 |
| Прибыль до налогообложения (без курсовой разницы) | млн. рублей USD млн.* | 5134 528 |
| Нераспределенная прибыль (по отчету) | млн. рублей USD млн.* | 118 12 |
| Нераспределенная прибыль (исключая курсовые разницы) | млн. рублей USD млн.* | 3220 331 |
| Активы (на конец года) | млн. рублей USD млн.* | 136482 6638 |
В связи с продолжавшимся в 1998 году падением мировых цен на нефтепродукты их экспорт составил 3,4 млн. т против 6,3 млн. в 1997 году. Для сохранения Компанией завоеванных позиций на мировом рынке нефтепродуктов объемы экспорта планируется довести в 1999 году до 5-6 млн. при условии улучшения рыночной конъюнктуры. Приоритетной задачей является создание стимулирующих условий для роста экспорта и извлечение максимально возможной прибыли.
Важным составляющим процесса продажи нефти и нефтепродуктов на экспорт, включая все формы контрактов, порядок установления цен, ответственность сторон и другое, является биржа. Она аккумулирует все процессы, происходящие на стадии покупки продажи данного товара, и помогает застраховаться от сопутствующих рисков.
Биржи, на которых проводятся торги нефтяными и нефтепродуктовыми фьючерсными контрактами: Нью-Йоркская товарная биржа (NYMEX) и Лондонская международная нефтяная биржа (IPE). Биржа- это оптовый рынок, юридически оформленный в виде организации торговцев. Развитие механизмов торговли фьючерсными контрактами и введение последних на все активы, которыми прежде торговали товарные, фьючерсные и валютные биржи, привело к стиранию различий между указанными видами бирж и к появлению либо фьючерсных бирж, на которых торгуют только фьючерсными контрактами, либо универсальных бирж, на которых торгуют как фьючерсными контрактами, так и традиционными биржевыми активами, например акциями, валютой и даже отдельными товарами.
Функции биржи заключаются в следующем:
организация биржевых собраний для проведения гласных публичных торгов;
разработку биржевых контрактов;
биржевой арбитраж, или разрешение споров, возникающих по заключенным биржевым сделкам в ходе биржевых торгов;
ценностная функция биржи. Данная функция имеет два аспекта. Первый - это, что задачей биржи становится выявление «истинно» рыночных цен, но одновременно и их регулирование с целью недопущения незаконных манипуляций с ценами на бирже. Второй - это ценопрогнозирующая функция биржи;
функция хеджирования, или биржевое страхование участников биржевой торговли от неблагоприятных для них колебаний цен. Функция хеджирования основывается на использовании механизма торговли фьючерсными контрактами. Суть этой функции состоит в том, что торговец - хеджер (т.е. тот, кто страхуется) - должен стать одновременно и продавцом товара, и его покупателем. В этом случае любое изменение цены его товара нейтрализуется, так как выигрыш продавца есть одновременно проигрыш покупателя и наоборот. Такая ситуация достигается тем, что хеджер, занимая, например, позицию покупателя на обычном рынке, должен занять противоположную позицию, в данном случае продавца, на рынке биржевых фьючерсных контрактов. Обычно производители товара хеджируются от снижения цен на их продукцию, а покупатели - от повышения цен на закупаемую продукцию:
спекулятивная биржевая деятельность;
функция гарантирования исполнения сделок. Достигается с помощью биржевых систем клиринга и расчетов;
информационная функция биржи.
Основными источниками информации о состоянии и перспективах развития мирового рынка нефти и нефтепродуктов являются публикации котировочных агентств Piatt"s (структурное подразделение крупнейшей американской издательской корпорации McGraw-Hill) и Argus Petroleum (независимая компания, Великобритания).
Котировки дают представление о диапазоне цен на конкретный сорт нефти за определенный день. Соответственно, они состоят из цены минимум (минимальной цены сделок или минимальной средневзвешенной цены предложения о покупке данного сорта нефти) и цены максимум (максимальная цена сделок или максимальная средневзвешенная цена предложения о продаже).
Точность котировок зависит от объема собранной информации. Первые данные по котировкам даются в режиме реального времени (их можно получать при наличии доступа к соответствующему оборудованию) в 21.00-22.00 по московскому времени. Эти данные могут корректироваться в случае поступления до конца дня новой информации по сделкам, уточняющей предварительные котировки. Окончательная версия котировок приводится в официальных печатных публикациях указанных агентств.
Котировки приводятся как по сделкам с немедленной поставкой - цены «спот» (поставка в течение двух недель, а по некоторым сортам нефти - в течение трех недель), так и по сделкам с отсроченной поставкой (по ключевым сортам нефти) - цены «форвард» (поставка через месяц, два месяца и три месяца).
Информация по котировкам «спот» и «форвард» является ключевым элементом в торговле нефтью на свободном рынке. Котировки «спот» используются для оценки правильности выбранной цены ранее заключенной «форвардной» сделки; для выписки инвойсов по поставкам, расчеты по которым осуществляются на основе формул, базирующихся на котировках «спот» на момент отгрузки товара; а также в качестве исходного пункта, с которого контрагенты начинают обсуждение ценовых условий сделок на следующий котировочный день.
Котировки «форвард», отражая фиксированные цены сделок с отсроченной поставкой, по существу представляют собой прогнозную оценку участниками рынка ситуации на месяц, два и три месяца вперед. В сочетании с котировками «спот», котировки «форвард» показывают наиболее вероятную на данный момент тенденцию изменения цен на данный сорт нефти на перспективу в один, два и три месяца.
Котировки приводятся для нефти данного сорта стандартного качества. Если качество конкретной партии нефти отличается от стандартного, то при заключении сделки цена партии устанавливается на базе котировок с учетом скидки или премии за качество.
Величина скидки или премии за качество зависит от того, в какой мере цена «нетбэк» конкретной партии товара отличается от цены «нетбэк» нефти данного сорта стандартного качества.
Резюмируя содержание всего сказанного, отметим, что для обеспечения эффективного экспорта нефти поставщик должен располагать данными по котировкам «спот», «форвард», ценам на нефтепродукты и фьючерсным позициям, информацией по ценам «нетбэк», фрахтовым и страховым ставкам, динамике спрэдов и запасов нефти. Минимальные информационные требования сводятся к знанию котировок «спот» и «форвард» на экспортируемую нефть и конкурентные сорта нефти, динамике спрэдов, фрахтовых и страховых ставок. К основным видам срочных контрактов, заключающихся на бирже, относятся:
Фьючерсный контракт - контракт на покупку и продажу товара в будущем по цене на момент заключения сделки.
Опцион - контракт, дающий право, но не обязательство, купить или продать фьючерсный контракт на нефть или нефтепродукты в будущем по желаемой цене. Опционами торгуют на тех же биржах, где торгуют фьючерсными контрактами.
Форвардная сделка - сделка, срок исполнения которой не совпадает с моментом ее заключения на бирже и оговаривается в контракте.
Сделка «спот» характеризуется тем, что срок ее заключения совпадает со сроком исполнения, и при такой сделке валюта должна быть поставлена сразу же (как правило, не позже двух рабочих дней после заключения сделки).
При заключении контракта особую роль играет точность прогноза ситуации на рынке по данному виду товара, а также прогноз цены на него. Поэтому мы считаем важным рассмотреть роль прогнозных оценок в достижении эффекта от торговли нефтью и нефтепродуктами.
При совершении перечисленных сделок есть один ключевой момент - это точность прогнозов. Конечно, с точки зрения теории, казалось бы, нам все равно, где будут цены в будущем. Открыв позицию, мы замкнули для себя цену продажи нефти, для нас она уже не может быть ни выше, ни ниже. Поэтому точный прогноз дает нам опцию на необходимые действия при изменении цены. Неверный прогноз означает убытки. Существует множество способов прогнозирования на рынке, но лишь некоторые из них заслуживают особого внимания. На протяжении многих лет прогнозирование финансовых рынков основывалось на теории рациональных ожиданий, анализе временных рядов и техническом анализе.
Согласно теории рациональных ожиданий, цены увеличиваются или уменьшаются вследствие того, что инвесторы рационально и немедленно реагируют на новую информацию: любые различия между инвесторами в отношении, к примеру, инвестиционных целей или доступной им информации игнорируются как статистически незначимые. Подобный подход основывается на предположении о полной информационной открытости рынка, т.е. на том, что ни один из его участников не обладает информацией, которой не обладали бы остальные участники. При этом не может существовать никаких конкурентных преимуществ, поскольку, обладая информацией, не доступной остальным, невозможно увеличить шансы для получения прибыли.
Целью анализа временных рядов является выявление определенного количества факторов, влияющих на изменение цен с помощью статистических методов. Этот подход позволяет выявить тенденции развития рынка, однако, если в рядах данных наблюдается повторяемость или однородные циклы, его применение может быть связано с серьезными трудностями.
Технический анализ представляет собой совокупность методов анализа и принятия решений, основанных только на исследовании внутренних параметров фондового рынка: цен, объемов сделок и величины открытого интереса (числа открытых контрактов на покупку и на продажу). Все многообразие методов прогнозирования технического анализа можно разделить на две большие группы: графические методы и аналитические методы.
Графический технический анализ - это анализ различных рыночных графических моделей, образующихся определенными закономерностями движения цен на графиках, с целью предположения вероятности продолжения или смены существующего тренда. Рассмотрим основные типы графиков:
Линейный. На линейном графике отмечают только цену закрытия для каждого последующего периода. Рекомендуется на коротких отрезках (до нескольких минут).

График отрезков (бары) - на баровом графике изображают максимальную цену (верхняя точка столбика), минимальную цену (нижняя точка столбика), цену открытия (черточка слева от вертикального столбика) и цену закрытия (черточка справа от вертикального столбика). Рекомендуется для промежутков времени от 5 минут и более.

Японские свечи (строятся по аналогии с барами).

Крестики-нолики - нет оси времени, а новая колонка цен строится после появления другого направления динамики. Крестик рисуется, если цены снизились на определенное количество пунктов (критерий риверсировки), если цены повысились на определенное количество пунктов, то рисуется нолик.

Арифметическая и логарифмическая шкалы. Для некоторых видов анализа, особенно если речь идет об анализе долгосрочных тенденций, удобно пользовать шкалой логарифмической. В арифметической шкале расстояния между делениями неизменны. В логарифмической шкале одинаковое расстояние соответствует одинаковым в процентном отношении изменениям.
Графики объема.

Постулатами этого вида технического анализа являются перечисленные ниже основные понятия технического анализа: линии тенденции, уровни рыночного сопротивления и поддержки, уровни коррекции текущего тренда. Например:

Линии сопротивления (Resistance):
возникают, когда покупатели больше либо не могут, либо не хотят покупать данный товар по более высоким ценам. Давление продавцов превосходит давление со стороны покупателей, в результате рост останавливается и сменяется падением;
соединяют важные максимумы (вершины) рынка.

Линии поддержки (Support):
соединяют важные минимумы (низы) рынка;
возникают, когда продавцы больше либо не могут, либо не хотят продавать данный товар по более низким ценам. При данном уровне цены стремление купить достаточно сильно и может противостоять давлению со стороны продавцов. Падение приостанавливается, и цены вновь начинают идти вверх.

Спускаясь, линия поддержки превращается в сопротивление. Поднимаясь, линия сопротивления превращается в поддержку.

В случае, если цены колеблются между двумя параллельными прямыми линиями (линиями канала) можно говорить о наличии повышательного (понижательного или горизонтального) канала.

Различают два вида графических моделей:
1. Модели перелома тенденции- образующиеся на графиках модели, которые при выполнении некоторых условий могут предвосхищать смену существующего на рынке тренда. К ним относятся такие модели, как «голова-плечи», «двойная вершина», «двойное основание», «тройная вершина», «тройное основание».
Рассмотрим некоторые из них.
«Голова - плечи» - подтверждает разворот тренда.

Рис.13.22. 1-первая вершина; 2-вторая вершина; 3-лини шеи
HeadShoulders - голова - плечи.

Рис.13.23. 1-вершина левого плеча; 2-вершина головы;3-вершина правого плеча; 4-линия шеи.
2. Модели продолжения тенденции - образующиеся на графиках модели, которые при выполнении некоторых условий позволяют утверждать, что существует вероятность продолжения текущей тенденции. Возможно, тенденция развивалась слишком быстро и временно вступила в состояние перекупленности или перепроданности. Тогда после промежуточной коррекции она продолжит свое развитие в направлении прежней тенденции. В этой группе выделяют такие модели, как «треугольники», «алмазы», «флаги», «вымпелы» и другие. Например:


Как правило, эти фигуры заканчивают свое формирование на расстоянии от вершины P (древко) равное:
опред-е">
Треугольник

Треугольников на рынке следует бояться. Р- ценовая база. Т- временная база. Пробой фигуры происходит на расстоянии: ">
сбор и хранение данных - возможных участников прогноза (либо в качестве критерия, либо в качестве прогнозируемой величины, либо как и то и другое);
определение для рассматриваемого тренда или набора критериев (причем не всегда могут быть использованы данные, непосредственно хранящиеся в базе данных, зачастую требуется произвести некоторые преобразования данных, например, рационально в качестве критериев использовать относительные изменения величин);
выявление зависимости между прогнозируемой величиной и набором критериев в виде некоторой функции;
вычисление интересующей величины в соответствии с определенной функцией, значениями критериев на прогнозируемый момент и видом прогноза - краткосрочный или долгосрочный).
В практической части работы на основе исторических данных какого-либо тренда за некоторый временной промежуток (месяц, год, несколько лет), представленных также в некотором масштабе времени (минутные, 5-минутные, получасовые, дневные и пр. котировки) нам необходимо получить прогноз развития котировок на несколько дискретов времени вперед. Информация о котировках активов представлена всеми или частью стандартных параметров, описывающих котировки за дискрет времени: цены открытия, закрытия, максимальная, минимальная, объем торгов на момент закрытия, открытый интерес.
Применение нейронных сетей для получения быстрого и качественного прогноза можно рассмотреть на рис. 13.27 «Технологическая схема прогнозирования на фондовом рынке с использованием нейронных сетей».
Для полноценного прогноза тенденций трех наиболее развитых в нашей стране рынков, включающих в себя множество финансовых инструментов, необходимо достаточное количество исходных для прогноза данных. Как видно из схемы, на данный момент реализовано поступление следующей информации:
информационно-торговые данные агентства «REUTERS», «DOW JONES TELERATE», «BLOOMBERG»;
торговые данные с площадок ММВБ и РТС;
прочие данные посредством ручного ввода.
Все необходимые данные поступают в базу данных (БД MS SQL Server). Далее происходит выбор и подготовка данных для участия в прогнозе. На этом предварительном этапе встает задача выбора из более 200 видов информационно-торговых данных наиболее значимых критериев для прогноза интересующей стоимостной величины некоторого финансового инструмента или группы финансовых инструментов. Первичный выбор критериев осуществляется аналитиком и зависит от опыта и интуиции последнего. В помощь аналитику предоставляются инструменты технического анализа, представляемые в виде графиков, анализируя которые можно уловить скрытые взаимосвязи. Выделяется временной ряд прогнозирования.
Затем обработанные данные поступают в нейросетевой пакет STATIS-TICA Neural Networks, где с помощью обученного персептрона происходит распознавание 5-дневных периодов. Каждому из периодов сеть присваивает одно из четырех показателей, характеризующих изменения тренда (как чарты в техническом анализе): стабильный период, восходящий, нисходящий, неопределенный. На основе обработанных данных сеть строит прогноз, но чтобы добиться уточнения полученных результатов, мы усложняем процесс прогнозирования. Дальнейшая обработка происходит в системе STATIST1CA. Данные не нуждаются в преобразовании, так как одинаковы по типу.
В процессе обработки временного ряда в пакете STATISTICA в модуле TIME Series/ Forecasting с помощью экспоненциального сглаживания (exponential smoothing forecasting), выделяется тренд, который разбивается на равные (5-дневные периоды) для последующего краткосрочного прогнозирования. Настройка тренда производится по одному из четырех представленных методов (линейный, экспоненциальный, горизонтальный, полиномиальный). Мы для своего эксперимента выбрали экспоненциальный метод. Обработали тренд и получили данные по его сглаживанию. Эти данные снова поступают на нейросетевую обработку с помощью многослойного персептрона. Обучение производится методом экспоненциального сглаживания, в результате которого сеть подтверждает правильность полученного ранее прогноза. Просмотреть результаты можно с помощью функции архивации.
Полученные прогнозируемые величины анализируются трейдером, в результате чего принимается правильное решение по проведению операций с ценными бумагами.
Один из подходов к решению проблемы анализа и прогнозирования фондового рынка базируется на циклической природе развития экономических процессов. Проявлением цикличности является волнообразное развитие экономических периодов. При прогнозировании временных рядов в экономике невозможно правильно оценить ситуацию и сделать достаточно точный прогноз без учета того, что на линию тренда накладываются циклические колебания. В современной экономической науке известны более 1380 видов цикличности. Экономика оперирует по преимуществу со следующими четырьмя:
Циклы Китчина - циклы запасов. Китчин (1926г.) сосредоточил внимание на исследовании коротких волн длиной от 2-х до 4-х лет на основе анализа финансовых счетов и продажных цен при движении товарных запасов.
Циклы Жугляра . Этот цикл имеет и другие названия: бизнес-цикл, промышленный цикл и т.д. Циклы были обнаружены при изучении природы промышленных колебаний во Франции, Великобритании и в США на основе фундаментального анализа колебаний ставок процента и цен. Как оказалось, эти колебания совпали с циклом инвестиций, которые в свою очередь инициировали изменения ВНП, инфляции и занятости.
Циклы Кузнеца. Дж.Риггальмен, В.Ньюмен в 1930-е гг. и некоторые другие аналитики построили первые статистические индексы совокупного годового объема жилищного строительства и обнаружили в них следующие друг за другом длительные интервалы быстрого роста и глубоких спадов или застоя. Тогда и появился впервые термин «строительные циклы».
Циклы Кондратьева. Большие циклы можно рассматривать как нарушение и восстановление экономического равновесия длительного периода. Основная их причина лежит в механизме накопления, аккумулирования и рассеяния капитала достаточного для создания основных производственных сил. Однако действие этой основной причины усиливает действие вторичных факторов. В соответствии с изложенным, развитие большого цикла принимает следующее освещение. Начало подъема совпадает с моментом, когда накопление и аккумулирование капитала достигает такого напряжения, при котором становится возможным рентабельное инвестирование капитала в целях производительных сил и радикального переоборудования техники. Причем, согласно основным «истинам» Кондратьева, в период повышательной волны большого цикла средние и короткие волны характеризуются краткостью дисперсий и интенсивностью подъемов, а в периоды понижательной волны большого цикла наблюдается обратная картина.
На фондовом рынке данные колебания проявляются в следующих друг за другом подъемах и спадах уровней деловой активности на протяжении некоторого периода времени: пик цикла, спад, низшая точка и фаза оживления.
В данной работе мы исходим из того, что колебания цен на рынке ценных бумаг являются результатом суперпозиции различных указанных выше волн и рядов случайных, стохастических факторов. Делается попытка выявить наличие циклов и определить фазу, в которой находится процесс. В зависимости от этого строится прогноз дальнейшего развития процесса с использованием средств ARIMA при подходящих предположениях о параметре процесса.
Переходы системы представляют собой суперпозицию волн различной длины. Как известно, волны имеют несколько фаз, сменяющих друг друга. Это может быть фаза оживления, спада или застоя. Если этим фазам присвоить символьные значения А, В, С, то их можно представить в виде последовательности примитивов (подобных чартам в техническом анализе) и, распознав эти последовательности (которые также представляют собой периоды подъема, спада, застоя, т.е. а,b,с, только более мелкого масштаба), мы можем, основываясь на правилах распознающих грамматик с некоторой вероятностью формула" src="http://hi-edu.ru/e-books/xbook725/files/28.gif" border="0" align="absmiddle" alt=". Затем мы можем также рассмотреть последовательности вида AAABBCD…. .Получается, что мы распознали и саму волну, и ее фазу.
Теперь мы можем сделать не только более точный краткосрочный прогноз, но и можем проследить общую динамику фондового рынка в перспективе (определив фазу длинной волны, мы можем судить о характере следующей, т.к. фазы протекают в определенной последовательности). В нашем эксперименте мы попытались обучить персептрон распознаванию фаз волн (А, В, С, D).
Для эксперимента были взяты данные итогов торгов с РТС по акциям компании ЛУКОЙЛ (LKON) за период с 01 июня 1998г. по 31 декабря 1999 г. В исходную БД вошли следующие переменные: средневзвешенная цена покупки, средневзвешенная цена продажи, максимальная дневная цена, минимальная дневная цена, количество сделок. База данных со значениями перечисленных переменных была импортирована в среду Excel из Интернета, а затем перенесены в пакет SNW. Подробнее эта процедура рассмотрена на рис. 13.28 - веса, которые принимают отдельные наблюдения ряда.
Ширина интервала сглаживания бралась равной 4 наблюдениям. Затем числовое выражение тренда (рис 13.30 ) были добавлены в новую переменную smoothing.
Таким образом, мы сформировали БД с переменными, которые будут подаваться на вход нейронной сети. Причем т.к. SNW полностью совместима с SNN специально импортировать данные в SNN не было необходимости. На входе предполагалось получить значения типа a,b,c,d, но для этого персептрон должен был распознать фазу, в которой мы находимся и на ее основании сделать более точный краткосрочный прогноз. Другими словами, он должен рассмотреть последовательности примитивов и идентифицировать их с фазами цикла. Причем фазы цикла типа A,B,C,D персептрон на выход не выдает.
Для реализации поставленной задачи обучения персептрона выделяется мобильное окно шириной 5 дней. Одно временное окно состоит из последовательности примитивов а, b, с или d. Таким образом, более точный прогноз может быть получен путем кусочной аппроксимации числового тренда по средневзвешенной цене покупки.
Чтобы обучить персептрон распознать пятидневные последовательности и идентифицировать их как А, В, С или D, нам пришлось для некоторого числа вариантов самим определить их фазу и добавить наши результаты в новую переменную исходной БД (state). Таким образом, окончательно сформированная БД содержит значения следующих переменных: средневзвешенная цена покупки, средневзвешенная цена продажи, максимальная дневная цена, минимальная дневная цена, количество сделок, тренд, выделенный относительно средневзвешенной цены покупки и, наконец, переменная, определяющая состояние экономического процесса. На вход подавались все переменные, кроме последней. Ее предполагалось получить только на выходе, чтобы персептрон при обучении не реагировал на значение этой переменной, а подгонял веса таким образом, чтобы на выходе могли получиться только четыре значения: А, В, С, D, а затем, согласно распознанному состоянию, а также учитывал, что после фазы подъема следует фаза постоянства, а затем вновь спада, и на этой основе был способен сделать краткосрочный прогноз. Таким образом, для прогноза собраны все данные. Теперь остается только один вопрос: какие параметры выбрать для сети и каким методом обучать. В связи с этим был проведен ряд экспериментов и в результате сделаны следующие выводы.
Первоначально предполагалось обучать многослойный персептрон методом обратного распространения ошибок. На вход подавалось 7 переменных (они перечислены выше), на выход- только одна- STATE. Кроме входного и выходного слоев строился один промежуточный слой, состоящий из 6, а затем из 8 нейронов. Ошибка обучения составляла примерно 0,2-0,4, однако на переходные состояния персептрон реагировал слабо. Поэтому мы решили сначала увеличить количество нейронов в среднем слое до 14, а затем сменили метод обучения персептрона («сопряженных градиентов»). Ошибка стала колебаться в пределах 0.12-0,14, причем все множество значений переменных рассматривалось как обучающее.
В результате экспериментов оптимальной получилась нейронная сеть со следующими параметрами: на вход подается 7 переменных: Smoothly, Average, Open_Buy, VoLTrad. Val_Q, Min_PR, Max_PR, на выход - STATE. Обучение проводилось с шагом 6, методом сопряженных градиентов, всего- 3 слоя (на первом 7 нейронов, на втором- 14, на третьем- 3) (рис. 13.29 ), в результате персептрон четко реагировал на состояния тренда (восходящий - 1 нейрон выходного слоя, нисходящий ndash; 2 нейрон выходного слоя и горизонтальный - 3 нейрон) (рис. 13.31 ).
В результате проведенных исследований был произведен отбор данных- возможных объектов прогноза, определили прогнозируемые величины и наборы критериев, а также выявили зависимости между ними.
В процессе эксперимента, было установлено, что выделение тренда увеличивает скорость обучения многослойного персептрона, и при определенном регулировании сети распознает восходящий, нисходящий и горизонтальный тренды.
Полученные положительные результаты дают возможность перейти к более глубокому изучению циклических зависимостей на рынках, и использовать при проведении финансовых операций другие методы нейронный технологий (карты Кохонена).
Нечёткие нейронные сети (fuzzy- neural networks ) осуществляют выводы на основе аппарата нечёткой логики , однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения нейронных сетей (НС). Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки , изначально предложенный для обучения многослойного персептрона . Для этого модуль нечёткого управления представляется в форме многослойной сети. Нечёткая нейронная сеть, как правило, состоит из четырех слоёв: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечётких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечёткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечёткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечёткие системы
Классические нечёткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удаётся обеспечить. Адаптивные нечёткие системы (adaptive fuzzy systems ) решают эту проблему. В таких системах подбор параметров нечёткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечётких систем относительно трудоёмки и сложны по сравнению с алгоритмами обучения нейронных сетей , и, как правило, состоят из двух стадий:
- Генерация лингвистических правил;
- Корректировка функций принадлежности.
Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определённое противоречие: для генерации нечётких правил необходимы функции принадлежности , а для проведения нечёткого вывода – правила. Кроме того, при автоматической генерации нечётких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечётких систем использует генетические алгоритмы . В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems .
Значительный вклад в развитие теории и практики нечётких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечёткие запросы
Нечёткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент даёт возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съёме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов . Для этой цели разработана нечёткая реляционная алгебра и специальные расширения языков SQL для нечётких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде .
Нечёткие ассоциативные правила
Нечёткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечёткой транзакции, поддержки и достоверности нечёткого ассоциативного правила.
Нечёткие когнитивные карты
Нечёткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечёткие когнитивные карты представляют собой нечёткий ориентированный граф, узлы которого являются нечёткими множествами. Направленные рёбра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечётких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и с лёгкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддаётся формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечёткая кластеризация
Нечёткие методы кластеризации, в отличие от чётких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечёткая кластеризация во многих ситуациях более "естественна", чем чёткая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечёткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
11.3. Нейронные сети в экономике
Область ИИ, нашедшая наиболее широкое применение - нейронные сети . Основная их особенность - это способность к самообучению на конкретных примерах.
Нейросети предпочтительны там, где имеется очень много входных данных, в которых скрыты закономерности. Целесообразно использовать нейросетевые методы в задачах с неполной или "зашумлённой" информацией, а также в таких, где решение можно найти интуитивно.
Нейросети применяются для предсказания рынков, оптимизации товарных и денежных потоков, анализа и обобщения социологических опросов, предсказание динамики политических рейтингов, оптимизации производственного процесса, комплексной диагностики качества продукции и для многого, многого другого.
Нейронные сети всё чаще применяются и в реальных бизнес - приложениях. В некоторых областях, таких как обнаружение фальсификаций и оценка риска , они стали бесспорными лидерами среди используемых методов. Их использование в системах прогнозирования и системах маркетинговых исследований постоянно растёт.
Поскольку экономические, финансовые и социальные системы очень сложны и являются результатом действий и противодействий различных людей, то является очень сложным (если не невозможным) создать полную математическую модель с учётом всех возможных действий и противодействий. Практически невозможно детально аппроксимировать модель, основанную на таких традиционных параметрах, как максимизация полезности или максимизация прибыли.
В системах подобной сложности является естественным и наиболее эффективным использовать модели, которые напрямую имитируют поведение общества и экономики. А это как раз то, что способна предложить методология нейронных сетей .
Ниже перечислены области, в которых эффективность применения нейронных сетей доказана на практике:
Для финансовых операций:
- Прогнозирование поведения клиента.
- Прогнозирование и оценка риска предстоящей сделки.
- Прогнозирование возможных мошеннических действий.
- Прогнозирование остатков средств на корреспондентских счетах банка.
- Прогнозирование движения наличности, объёмов оборотных средств.
- Прогнозирование экономических параметров и фондовых индексов.
Для планирования работы предприятия:
- Прогнозирование объёмов продаж.
- Прогнозирование загрузки производственных мощностей.
- Прогнозирование спроса на новую продукцию.
Для бизнес - аналитики и поддержки принятия решений :
- Выявление тенденций, корреляций, типовых образцов и исключений в больших объёмах данных.
- Анализ работы филиалов компании.
- Сравнительный анализ конкурирующих фирм.
Другие приложения:
- Оценка стоимости недвижимости.
- Контроль качества выпускаемой продукции.
- Системы слежения за состоянием оборудования.
- Проектирование и оптимизация сетей связи, сетей электроснабжения.
- Прогнозирование потребления энергии.
- Распознавание рукописных символов, в т.ч. автоматическое распознавание и аутентификация подписи.
- Распознавание и обработка видео - и аудио сигналов.
Нейронные сети могут быть использованы и в других задачах. Основными предопределяющими условиями их использования являются наличие "исторических данных", используя которые нейронная сеть сможет обучиться, а также невозможность или неэффективность использования других, более формальных, методов.
Независимый экспертный совет по стратегическому анализу проблем внешней и внутренней политики при Совете Федерации НИИ искусственного интеллекта представил проект "Технология нового поколения на основе недоопределённых вычислений и её использование для разработки экспериментальной модели макроэкономики РФ". Появилась возможность просчитывать исход любого действия или предложения, касающегося бюджета страны, на много лет вперёд.
Система позволяет видеть, как изменится доходная часть, дефицит бюджета, объём промышленного производства в ответ, скажем, на увеличение налогов. Также можно посмотреть, сколько денег в прошлом году уплыло из бюджета: электронная машина, по уверению учёных, легко сможет справиться и с такой задачей. Ей даже не надо будет объяснять понятие "чёрный нал".
Можно решить и обратную задачу. Например, а что надо сделать, чтобы к 2020 году объём производства увеличился или, скажем, хотя бы не падал? Машина укажет нижнюю и верхнюю границу значений в том и другом случае для отпускаемых бюджетных денег по всем параметрам, так или иначе влияющим на производство.
Кроме того, можно узнать не по гороскопу и без помощи магов возможную последовательность "критических" и "удачных" моментов в развитии экономики страны при заданных исходных данных.
Разработчики проекта создали пока лишь демонстрационную модель, охватывающую около 300 параметров и период от 1990-го до 1999 года. Но для нормальной работы необходимо не менее 1000 параметров. И такая работа может быть проведена, если на неё будут отпущены средства. Надо провести множество прикладных работ , необходимы фундаментальные исследования по обоим основным составляющим проекта - математической и экономической. Здесь нужна серьёзная государственная материальная поддержка .
Внедрение действующей компьютерной модели макроэкономики и госбюджета РФ позволит автоматизировать подготовку исходных параметров госбюджета очередного года, согласование окончательного варианта для утверждения в парламенте, поддержку, оценку и контроль исполнения бюджета на всех его этапах.
Интерес к искусственным нейронным сетям в России очень вырос за последние несколько лет. Возможность быстрого обучения и достоверность выводов позволяет рекомендовать нейросетевые экспертные системы как один из обязательных инструментов во многих аспектах современного бизнеса. Нейронные сети обладают огромным преимуществом перед традиционным трудозатратным и более длительным путём обобщения знаний людей-экспертов.
Технологии нейронных сетей применимы практически в любой области, а в таких задачах, как прогнозирование котировок акций и курса валют они стали уже привычным и широко используемым инструментом. Повсеместное проникновение нейросетевых технологий в современный бизнес - только вопрос времени. Внедрение новых наукоёмких технологий - это процесс сложный, однако практика показывает, что инвестиции не только окупаются и приносят выгоду, но и дают тем, кто их использует, ощутимые преимущества.
Применение нейронных сетей в финансах базируется на одном фундаментальном допущении: замене прогнозирования распознаванием. По большому счёту, нейросеть не предсказывает будущее, а "узнаёт" в текущем состоянии рынка ранее встречавшуюся ситуацию и воспроизводит последовавшую реакцию рынка.
Финансовый рынок достаточно инерционен, у него есть своя определённая "замедленная реакция ", зная которую можно довольно точно вычислять грядущую ситуацию. А насколько точно - это зависит от условий рынка и квалификации оператора.
Поэтому наивно верить, что нейросеть будет автоматически предсказывать курсы основных индикаторов - национальной валюты или, например, драгоценных металлов на нестабильных рынках. Но при любой рыночной ситуации существуют инструменты, сохраняющие стабильность . Например, при скачках доллара - это "дальние" фьючерсы , реакция которых растягивается на несколько дней и поддаётся прогнозу. Кстати, в периоды рыночных потрясений игроки обычно паникуют, что усиливает преимущества владельца хорошего аналитического инструмента.
Над созданием нейронных сетей различного назначения в настоящее время трудятся сотни всемирно известных, а также мелких начинающих фирм. Мировой рынок предлагает более сотни нейросетевых пакетов, преимущественно - американских. Общий объём рынка нейронных сетей к 2005 году превысил $10 млрд. И, практически, каждый разработчик традиционных аналитических пакетов сегодня стремится включить нейронные сети в новые версии своих программ. В США нейронные сети применяются в аналитических комплексах каждого крупного банка.
Продажа одного только нейросетевого пакета "Brain Maker Pro" сравнима с объёмами продаж самого популярного пакета технического анализа MetaStock (в США продано более 20000 копий Brain Maker Pro).
Хорошо зарекомендовал себя пакет "The AI Trilogy". ("Трилогия искусственного интеллекта") американской фирмы "Ward Systems Group ". Это набор из трёх программ, каждая из которых может использоваться как самостоятельно, так и в комбинации с остальными.
Так, программа "NeuroShell II" - это набор из 16 типов нейронных сетей , "NeuroWindows" - нейросетевая библиотека с исходными текстами, "GeneHunter" - генетическая программа оптимизации. В совокупности они образуют мощный " конструктор ", позволяющий строить аналитические комплексы любой сложности.
"The AI Trilogy" на американском рынке пользуется большим спросом. Пакет установлен в 150 крупнейших банках США. Он многократно побеждал в престижных конкурсах популярных финансовых изданий и помогает управлять капиталами в несколько миллиардов долларов. Фирма "Du Pont" (институт стандартов США и ФБР) считает "Трилогию искусственного интеллекта" лучшей для решения различных задач.
Интересен и знаменателен малоизвестный факт, что ключевые компоненты этого пакета были написаны российскими программистами. Своим обликом пакет обязан группе разработчиков из небольшой московской компании "Нейропроект" под руководством профессора Персиянцева. Она более трёх лет выполняла заказы фирмы "Ward Systems Group " и нашла удачные решения. Можно сказать, что русские программы управляют финансами Америки и задачами ФБР!
Насколько может быть полезен пакет финансистам? В состоянии ли он будет работать на нашем непредсказуемом рынке, где одно решение Центробанка может мгновенно опрокинуть рынок? Предваряя эти вопросы, владельцы пакета предлагают специальную консалтинговую услугу.
С банком, аналитики которого не верят в прогнозируемость нашего рынка, заключается специальный договор. В течение определённого периода: две недели, месяц или больше, за символическую плату банку ежедневно предоставляются прогнозы на завтрашний день (или на неделю вперед) по котировкам заданных финансовых инструментов . Если прогноз стабильно демонстрирует приемлемую точность , то банк обязуется купить аналитический комплекс вместе с настройками.
И не было ни единого случая, когда клиент отказывался от покупки. Показательный и впечатляющий случай имел место между выборами, когда один из крупных банков проводил подобное тестирование пакета. Плясали курсы бумаг, падали и поднимались политики, но каждый вечер банк получал прогноз с набором завтрашних цен (мини – макси – средневзвешенная – закрытие) по шестнадцати бумагам ГКО. Не прошло и двух недель, как банк заключил договор на поставку аналитического комплекса, способного сохранять работоспособность даже в таких бурных и непредсказуемых ситуациях.
- Богатые возможности. Нейронные сети - исключительно мощный метод моделирования, позволяющий воспроизводить чрезвычайно сложные зависимости. В частности, нейронные сети нелинейны по свой природе. На протяжении многих лет линейное моделирование было основным методом моделирования в большинстве областей, поскольку для него хорошо разработаны процедуры оптимизации. В задачах, где линейная аппроксимация неудовлетворительна (а таких достаточно много), линейные модели работают плохо. Кроме того, нейронные сети справляются с "проклятием размерности", которое не позволяет моделировать линейные зависимости в случае большого числа переменных
- Простота в использовании. Нейронные сети учатся на примерах. Пользователь нейронной сети подбирает представительные данные, а затем запускает алгоритм обучения, который автоматически воспринимает структуру данных. При этом от пользователя, конечно, требуется какой-то набор эвристических знаний о том, как следует отбирать и подготавливать данные, выбирать нужную архитектуру сети и интерпретировать результаты, однако уровень знаний, необходимый для успешного применения нейронных сетей , гораздо скромнее, чем, например, при использовании традиционных методов статистики.
Нейронные сети привлекательны с интуитивной точки зрения, ибо они основаны на примитивной биологической модели нервных систем. В будущем развитие таких нейробиологических моделей может привести к созданию действительно мыслящих компьютеров. Между тем уже "простые" нейронные сети , которые строит система ST Neural Networks , являются мощным оружием в арсенале специалиста по прикладной статистике.
Параллели из биологии
Нейронные сети возникли из исследований в области искусственного интеллекта, а именно, из попыток воспроизвести способность биологических нервных систем обучаться и исправлять ошибки, моделируя низкоуровневую структуру мозга (Patterson, 1996). Основной областью исследований по искусственному интеллекту в 60-е - 80-е годы были экспертные системы. Такие системы основывались на высокоуровневом моделировании процесса мышления (в частности, на представлении, что процесс нашего мышления построен на манипуляциях с символами). Скоро стало ясно, что подобные системы, хотя и могут принести пользу в некоторых областях, не ухватывают некоторые ключевые аспекты человеческого интеллекта. Согласно одной из точек зрения, причина этого состоит в том, что они не в состоянии воспроизвести структуру мозга. Чтобы создать искусственный интеллект, необходимо построить систему с похожей архитектурой.
Мозг состоит из очень большого числа (приблизительно 10,000,000,000) нейронов, соединённых многочисленными связями (в среднем несколько тысяч связей на один нейрон , однако это число может сильно колебаться).
Нейроны - это специальные клетки, способные распространять электрохимические сигналы (рис.11.7).
Рис.
11.7.
Нейрон имеет разветвлённую структуру ввода информации (дендриты ), ядро и разветвляющийся выход (аксон ). Аксоны клетки соединяются с дендритами других клеток с помощью синапсов . При активации нейрон посылает электрохимический сигнал по своему аксону . Через синапсы этот сигнал достигает других нейронов, которые могут, в свою очередь, активироваться. Нейрон активируется тогда, когда суммарный уровень сигналов, пришедших в его ядро из дендритов , превысит определённый уровень (порог активации).
Интенсивность сигнала, получаемого нейроном (а, следовательно, и возможность его активации), сильно зависит от активности синапсов . Каждый синапс имеет протяженность, и специальные химические вещества передают сигнал вдоль него. Один из самых авторитетных исследователей нейросистем, Дональд Хебб, высказал постулат, что обучение заключается, в первую очередь, в изменениях "силы" синоптических связей . Например, в классическом опыте Павлова каждый раз непосредственно перед кормлением собаки звонил колокольчик, и собака быстро научилась связывать звонок колокольчика с пищей. Синоптические связи между участками коры головного мозга, ответственными за слух, и слюнными железами усилились, и при возбуждении коры звуком колокольчика у собаки начиналось слюноотделение.
Таким образом, будучи построен из очень большого числа совсем простых элементов (каждый из которых берёт взвешенную сумму входных сигналов и в случае, если суммарный вход превышает определённый уровень, передаёт дальше двоичный сигнал), мозг способен решать чрезвычайно сложные задачи. Разумеется, здесь не затронуто многих сложных аспектов устройства мозга, однако интересно то, что искусственные нейронные сети способны достичь замечательных результатов, используя модель, которая ненамного сложнее, чем описанная выше.
Базовая искусственная модель
Чтобы отразить суть биологических нейронных систем, определение искусственного нейрона даётся следующим образом:
- Он получает входные сигналы (исходные данные либо выходные сигналы других нейронов нейронной сети) через несколько входных каналов. Каждый входной сигнал проходит через соединение, имеющее определённую интенсивность (или вес); этот вес соответствует синоптической активности биологического нейрона . С каждым нейроном связано определённое пороговое значение. Вычисляется взвешенная сумма входов, из неё вычитается пороговое значение, и в результате получается величина активации нейрона (она также называется пост - синоптическим потенциалом нейрона - PSP ).
- Сигнал активации преобразуется с помощью функции активации (или передаточной функции), и в результате получается выходной сигнал нейрона .
При этом используется ступенчатая функция активации (т.е. выход нейрона равен нулю, если вход отрицательный, и единице, если вход нулевой или положительный). Такой нейрон будет работать точно так же, как описанный выше естественный нейрон (вычесть пороговое значение из взвешенной суммы и сравнить результат с нулем - это то же самое, что сравнить взвешенную сумму с пороговым значением). В действительности пороговые функции редко используются в искусственных нейронных сетях . Веса могут быть отрицательными, - это значит, что синапс оказывает на нейрон не возбуждающее, а тормозящее воздействие (в мозге присутствуют тормозящие нейроны).
Это было описание отдельного нейрона . Теперь возникает вопрос: как соединять нейроны друг с другом? Если сеть предполагается для чего-то использовать, то у неё должны быть входы (принимающие значения интересующих нас переменных из внешнего мира) и выходы (прогнозы или управляющие сигналы). Входы и выходы соответствуют сенсорным и двигательным нервам - например, соответственно, идущим от глаз и в руки. Кроме этого, однако, в сети может быть ещё много промежуточных ( скрытых) нейронов , выполняющих внутренние функции. Входные, скрытые и выходные нейроны должны быть связаны между собой.
Ключевой вопрос здесь - обратная связь (Haykin, 1994). Простейшая сеть имеет структуру прямой передачи сигнала: сигналы проходят от входов через скрытые элементы и в конце концов приходят на выходные элементы. Такая структура имеет устойчивое поведение. Если же сеть рекуррентная (т.е. содержит связи, ведущие назад от более дальних к более ближним нейронам), то она может быть неустойчива и иметь очень сложную динамику поведения. Рекуррентные сети представляют большой интерес для исследователей в области нейронных сетей , однако при решении практических задач, по крайней мере, до сих пор, наиболее полезными оказались структуры прямой передачи, и именно такой тип нейронных сетей моделируется в пакете ST Neural Networks .
Типичный пример сети с прямой передачей сигнала показан на рис.11.8 .

Рис. 11.8.
Нейроны регулярным образом организованы в слои. Входной слой служит просто для ввода значений входных переменных. Каждый из скрытых и выходных нейронов соединён со всеми элементами предыдущего слоя.
Можно было бы рассматривать сети, в которых нейроны связаны только с некоторыми из нейронов предыдущего слоя; однако, для большинства приложений сети с полной системой связей предпочтительнее, и именно такой тип сетей реализован в пакете ST Neural Networks .
При работе (использовании) сети во входные элементы подаются значения входных переменных, затем последовательно отрабатывают нейроны промежуточных и выходного слоев. Каждый из них вычисляет своё значение активации, беря взвешенную сумму выходов элементов предыдущего слоя и вычитая из неё пороговое значение. Затем значения активации преобразуются с помощью функции активации, и в результате получается выход нейрона . После того, как вся сеть отработает, выходные значения элементов выходного слоя принимаются за выход всей сети в целом.
Применение нейронных сетей
В предыдущем разделе в несколько упрощенном виде было описано, как нейронная сеть преобразует входные сигналы в выходные. Теперь возникает следующий важный вопрос: как применить нейронную сеть к решению конкретной задачи?
Класс задач, которые можно решить с помощью нейронной сети, определяется тем, как сеть работает и тем, как она обучается. При работе нейронная сеть принимает значения входных переменных и выдаёт значения выходных переменных. Таким образом, сеть можно применять в ситуации, когда у Вас имеется определённая известная информация, и Вы хотите из неё получить некоторую пока не известную информацию (Patterson, 1996; Fausett, 1994). Вот некоторые примеры таких задач:
Прогнозирование на фондовом рынке . Зная цены акций за последнюю неделю и сегодняшнее значение индекса FTSE, спрогнозировать завтрашнюю цену акций.
Предоставление кредита. Требуется определить, высок ли риск предоставления кредита частному лицу, обратившемуся с такой просьбой. В результате разговора с ним известен его доход, предыдущая кредитная история и т.д.
Управление. Нужно определить, что должен делать робот (повернуться направо или налево, двигаться вперёд и т.д.), чтобы достичь цели; известно изображение, которое передаёт установленная на роботе видеокамера.
Разумеется, вовсе не любую задачу можно решить с помощью нейронной сети. Если Вы хотите определить результаты лотереи, тираж которой состоится через неделю, зная свой размер обуви, то едва ли это получится, поскольку эти вещи не связаны друг с другом. На самом деле, если тираж проводится честно, то не существует такой информации, на основании которой можно было бы предсказать результат. Многие финансовые структуры уже используют нейронные сети или экспериментируют с ними с целью прогнозирования ситуации на фондовом рынке , и похоже, что любой тренд, прогнозируемый с помощью нейронных методов, всякий раз уже бывает "дисконтирован" рынком, и поэтому (к сожалению) эту задачу тоже вряд ли удастся решить.
Итак, мы приходим ко второму важному условию применения нейронных сетей : необходимо знать (или хотя бы иметь серьёзные подозрения), что между известными входными значениями и неизвестными выходами имеется связь. Эта связь может быть искажена шумом (так, едва ли можно ожидать, что по данным из примера с прогнозированием цен акций можно построить абсолютно точный прогноз, поскольку на цену влияют и другие факторы, не представленные во входном наборе данных, и, кроме того, в задаче присутствует элемент случайности), но она должна существовать.
Как правило, нейронная сеть используется тогда, когда неизвестен точный вид связей между входами и выходами, - если бы он был известен, то связь можно было бы моделировать непосредственно.
Другая существенная особенность нейронных сетей состоит в том, что зависимость между входом и выходом находится в процессе обучения сети. Для обучения нейронных сетей применяются алгоритмы двух типов (разные типы сетей используют разные типы обучения): управляемое ("обучение с учителем") и не управляемое ("без учителя"). Чаще всего применяется обучение с учителем, и именно этот метод сейчас рассмотрим.
Для управляемого обучения сети пользователь должен подготовить набор обучающих данных. Эти данные представляют собой примеры входных данных и соответствующих им выходов. Сеть учится устанавливать связь между первыми и вторыми. Обычно обучающие данные берутся из исторических сведений. В рассмотренных выше примерах это могут быть предыдущие значения цен акций и индекса FTSE, сведения о прошлых заемщиках - их анкетные данные и то, успешно ли они выполнили свои обязательства, примеры положений робота и его правильной реакции.
Затем нейронная сеть обучается с помощью того или иного алгоритма управляемого обучения (наиболее известным из них является метод обратного распространения, предложенный в работе Rumelhart et al., 1986), при котором имеющиеся данные используются для корректировки весов и пороговых значений сети таким образом, чтобы минимизировать ошибку прогноза на обучающем множестве. Если сеть обучена хорошо, она приобретает способность моделировать (неизвестную) функцию, связывающую значения входных и выходных переменных, и впоследствии такую сеть можно использовать для прогнозирования в ситуации, когда выходные значения неизвестны.
Сбор данных для нейронной сети
Если задача будет решаться с помощью нейронной сети, то необходимо собрать данные для обучения. Обучающий набор данных представляет собой набор наблюдений, для которых указаны значения входных и выходных переменных. Первый вопрос, который нужно решить, - какие переменные использовать и сколько (и каких) наблюдений собрать.
Выбор переменных (по крайней мере, первоначальный) осуществляется интуитивно. Опыт работы в данной предметной области поможет определить, какие переменные являются важными. При работе с пакетом ST Neural Networks можно произвольно выбирать переменные и отменять предыдущий выбор; кроме того, система ST Neural Networks умеет сама опытным путём отбирать полезные переменные. Для начала имеет смысл включить все переменные, которые могут влиять на результат - на последующих этапах следует сократить это множество.
Нейронные сети могут работать с числовыми данными, лежащими в определённом ограниченном диапазоне. Это создаёт проблемы в случаях, когда данные имеют нестандартный масштаб, когда в них имеются пропущенные значения и когда данные являются нечисловыми. В пакете ST Neural Networks имеются средства, позволяющие справиться со всеми этими трудностями. Числовые данные масштабируются в подходящий для сети диапазон, а пропущенные значения можно заменить на средние значения (или на другую статистику) этой переменной по всем имеющимся обучающим примерам (Bishop, 1995).
Более трудной задачей является работа с данными нечислового характера. Чаще всего нечисловые данные бывают представлены в виде номинальных переменных типа Пол = {Муж, Жен}. Переменные с номинальными значениями можно представить в числовом виде, и в системе ST Neural Networks имеются средства для работы с такими данными. Однако нейронные сети не дают хороших результатов при работе с номинальными переменными, которые могут принимать много разных значений.
Пусть, например, мы хотим научить нейронную сеть оценивать стоимость объектов недвижимости. Цена дома очень сильно зависит от того, в каком районе города он расположен. Город может быть подразделён на несколько десятков районов, имеющих собственные названия, и кажется естественным ввести для обозначения района переменную с номинальными значениями. К сожалению, в этом случае обучить нейронную сеть будет очень трудно, и вместо этого лучше присвоить каждому району определённый рейтинг (основываясь на экспертных оценках).
Нечисловые данные других типов можно либо преобразовать в числовую форму, либо объявить незначащими. Значения дат и времени, если они нужны, можно преобразовать в числовые, вычитая из них начальную дату (время). Обозначения денежных сумм преобразовать совсем несложно. С произвольными текстовыми полями (например, фамилиями людей) работать нельзя, и их нужно сделать незначащими.
Вопрос о том, сколько наблюдений нужно иметь для обучения сети, часто оказывается непростым. Известен ряд эвристических правил, увязывающих число необходимых наблюдений с размерами сети (простейшее из них гласит, что число наблюдений должно быть в десять раз больше числа связей в сети). На самом деле это число зависит также от (заранее неизвестной) сложности того отображения, которое нейронная сеть стремится воспроизвести. С ростом количества переменных количество требуемых наблюдений растёт нелинейно, так что уже при довольно небольшом (например, пятьдесят) числе переменных может потребоваться огромное число наблюдений.
Для большинства реальных задач бывает достаточно нескольких сотен или тысяч наблюдений. Для особо сложных задач может потребоваться еще большее количество, однако очень редко может встретиться (даже тривиальная) задача, где хватило бы менее сотни наблюдений. Если данных меньше, чем здесь сказано, то на самом деле недостаточно информации для обучения сети, и лучшее, что можно сделать - это попробовать подогнать к данным некоторую линейную модель.
В пакете ST Neural Networks реализованы средства для подгонки линейных моделей (см. раздел про линейные сети, а также материал по модулю Множественная регрессия системы STATISTICA).
Во многих реальных задачах приходится иметь дело с не вполне достоверными данными. Значения некоторых переменных могут быть искажены шумом или частично отсутствовать. Пакет ST Neural Networks имеет специальные средства работы с пропущенными значениями (они могут быть заменены на среднее значение этой переменной или на другие её статистики), так что если не так много данных, то можно включить в рассмотрение случаи с пропущенными значениями (хотя, конечно, лучше этого избегать). Кроме того, нейронные сети в целом устойчивы к шумам. Однако у этой устойчивости есть предел. Например, выбросы, т.е. значения, лежащие очень далеко от области нормальных значений некоторой переменной, могут исказить результат обучения. В таких случаях лучше всего постараться обнаружить и удалить эти выбросы (либо удалив соответствующие наблюдения, либо преобразовав выбросы в пропущенные значения). Если выбросы выявить трудно, то можно воспользоваться имеющимися в пакете ST Neural Networks возможностями сделать процесс обучения устойчивым к выбросам (с помощью функции ошибок типа "городских кварталов"; см. Bishop, 1995). Однако такое устойчивое к выбросам обучение, как правило, менее эффективно, чем стандартное.
Следовательно, при работе с НС необходимо выбирать такие переменные, которые, по предположению, влияют на результат.
С числовыми и номинальными переменными в пакете ST Neural Networks можно работать непосредственно. Переменные других типов следует преобразовать в указанные типы или объявить незначащими.
Для анализа нужно иметь порядка сотен или тысяч наблюдений; чем больше в задаче переменных, тем больше нужно иметь наблюдений. Пакет ST Neural Networks имеет средства для распознавания значимых переменных, поэтому следует включать в рассмотрение переменные, в значимости которых нет уверенности.
В случае необходимости можно работать с наблюдениями, содержащими пропущенные значения. Наличие выбросов в данных может создать трудности. Если возможно, следует удалить выбросы. Если данных достаточное количество, следует убрать из рассмотрения наблюдения с пропущенными значениями.
Пре/пост процессирование
Всякая нейронная сеть принимает на входе числовые значения и выдаёт на выходе также числовые значения. Передаточная функция для каждого элемента сети обычно выбирается таким образом, чтобы её входной аргумент мог принимать произвольные значения, а выходные значения лежали бы в строго ограниченном диапазоне. При этом, хотя входные значения могут быть любыми, возникает эффект насыщения, когда элемент оказывается чувствительным лишь к входным значениям, лежащим в некоторой ограниченной области. На этом рисунке представлена одна из наиболее распространённых передаточных функций - так называемая логистическая функция (рис.11.9) (иногда её также называют сигмоидной функцией, хотя если говорить строго, это всего лишь один из частных случаев сигмоидных - т.е. имеющих форму буквы S - функций). В этом случае выходное значение всегда будет лежать в интервале (0,1), а область чувствительности для входов чуть шире интервала (-1,+1). Данная функция является гладкой, а её производная легко вычисляется - это обстоятельство весьма существенно для работы алгоритма обучения сети (в этом также кроется причина того, что ступенчатая функция для этой цели практически не используется).

Рис. 11.9.
Коль скоро выходные значения всегда принадлежат некоторой ограниченной области, а вся информация должна быть представлена в числовом виде, очевидно, что при решении реальных задач методами нейронных сетей требуются этапы предварительной обработки - пре-процессирования - и заключительной обработки - пост-процессирования данных (Bishop, 1995). Соответствующие средства имеются в пакете ST Neural Networks . Здесь нужно рассмотреть два вопроса:
Шкалирование. Числовые значения должны быть приведены в масштаб, подходящий для сети. Обычно исходные данные масштабируются по линейной шкале. В пакете ST Neural Networks реализованы алгоритмы минимакса и среднего/стандартного отклонения, которые автоматически находят масштабирующие параметры для преобразования числовых значений в нужный диапазон.
В некоторых случаях более подходящим может оказаться нелинейное шкалирование (например, если заранее известно, что переменная имеет экспоненциальное распределение, имеет смысл взять ее логарифм). Нелинейное шкалирование не реализовано в модуле ST Neural Networks . Вы можете прошкалировать переменную средствами преобразования даных базовой системы STATISTICA, а затем работать с ней в модуле ST Neural Networks .
Номинальные переменные. Номинальные переменные могут быть двузначными (например, Пол ={Муж, Жен}) или многозначными (т.е. принимать более двух значений или состояний). Двузначную номинальную переменную легко преобразовать в числовую (например, Муж = 0, Жен = 1). С многозначными номинальными переменными дело обстоит сложнее. Их тоже можно представить одним числовым значением (например, Собака = 0, Овца = 1, Кошка = 2), однако при этом возникнет (возможно) ложное упорядочивание значений номинальной переменной: в рассмотренном примере Овца окажется чем-то средним между Собакой и Кошкой. Существует более точный способ, известный как кодирование 1-из-N, в котором одна номинальная переменная представляется несколькими числовыми переменными. Количество числовых переменных равно числу возможных значений номинальной переменной; при этом всякий раз ровно одна из N переменных принимает ненулевое значение (например, Собака = {1,0,0}, Овца = {0,1,0}, Кошка = {0,0,1}). В пакете ST Neural Networks имеются возможности преобразовывать как двух-, так и многозначные номинальные переменные для последующего использования в нейронной сети. К сожалению, номинальная переменная с большим числом возможных состояний потребует при кодировании методом 1-из-N очень большого количества числовых переменных, а это приведёт к росту размеров сети и создаст трудности при её обучении. В таких ситуациях возможно (но не всегда достаточно) смоделировать номинальную переменную с помощью одного числового индекса, однако лучше будет попытаться найти другой способ представления данных.
Задачи прогнозирования можно разбить на два основных класса: классификация и регрессия.
В задачах классификации нужно бывает определить, к какому из нескольких заданных классов принадлежит данный входной набор. Примерами могут служить предоставление кредита (относится ли данное лицо к группе высокого или низкого кредитного риска), диагностика раковых заболеваний (опухоль, чисто), распознавание подписи (поддельная, подлинная). Во всех этих случаях, очевидно, на выходе требуется всего одна номинальная переменная. Чаще всего (как в этих примерах) задачи классификации бывают двузначными, хотя встречаются и задачи с несколькими возможными состояниями.
В задачах регрессии требуется предсказать значение переменной, принимающей (как правило) непрерывные числовые значения: завтрашнюю цену акций, расход топлива в автомобиле, прибыли в следующем году и т.п.. В таких случаях в качестве выходной требуется одна числовая переменная.
Нейронная сеть может решать одновременно несколько задач регрессии и/или классификации, однако обычно в каждый момент решается только одна задача. Таким образом, в большинстве случаев нейронная сеть будет иметь всего одну выходную переменную; в случае задач классификации со многими состояниями для этого может потребоваться несколько выходных элементов (этап пост-процессирования отвечает за преобразование информации из выходных элементов в выходную переменную).
В пакете ST Neural Networks для решения всех этих вопросов реализованы специальные средства пре- и пост-процессирования, которые позволяют привести сырые исходные данные в числовую форму, пригодную для обработки нейронной сетью, и преобразовать выход нейронной сети обратно в формат входных данных. Нейронная сеть служит "прослойкой"между пре- и пост-процессированием, и результат выдаётся в нужном виде (например, в задаче классификации выдается название выходного класса). Кроме того, в пакете ST Neural Networks пользователь может (если пожелает) получить прямой доступ к внутренним параметрам активации сети.